강화학습 논문 리뷰 연재 여섯 번째 입니다.
현재 감사하게도 함께 하고있는, '로봇이 아닙니다' 팀블로그에 합류한 이후 처음으로 쓰는 연재글이다 보니 퀄리티에 신경을 쓰려고 노력했고, 그러다 보니 예상 기간보다 일주일 이상!? 늦게 글을 올리게 되었습니다.
강화학습, 로보틱스, 딥러닝 관련 포스팅에 관심 많으신 분들은 밑의 블로그도 한 번 들러주세요 ^^
로봇이 아닙니다.
당황했습니까? 휴먼
ropiens.tistory.com
본론으로 돌아와, 이번 논문 리뷰글은 Multi-goal 강화학습, 희소 보상 환경 문제와 관련된 Hindsight Experience Replay(이하 HER)에 대한 내용으로 이루어져 있습니다. HER의 컨셉을 간단히 말씀 드리면, 사람처럼 실패를 통해 학습하여, 목표에 도달할 수 있는 agent를 설계하고 싶다! 입니다.
그럼, 본격적인 리뷰 시작하겠습니다!

논문의 제목은 상당히 아리송 합니다. 'Hind'라는 단어에는 뒤라는 뜻이 있고, 'sight'은 보다인 see의 과거형이죠. 그래서, 'Hindsight' 이란 단순하게는 뒤를 본다 라는 뜻이라고 합니다. 다른 뜻으로는 뒤를 보아 깨닫는다라는 뜻도 있다고 합니다.
그리하여, 제목의 뜻하는 바는, '경험 메모리를 통해 뒤를 보고 깨닫는 컨셉의 알고리즘' 정도로 의역할 수 있을 것 같습니다. 댓글을 통해 더욱 좋은 번역에 대해 토의를 나누길 기대합니다!

목차는 다음과 같습니다.
가장 먼저, 도입부에서는, 강화학습에서 중요한 문제인 탐험과 이용의 딜레마 문제와, HER에서 해결하고자 했던 희소 보상 문제 등을 몇 몇 환경을 예시로 들어 설명드리려고 합니다.
그 후, 본론에서는, HER을 더욱 잘 이해하기 위한 배경에 대해(on policy vs off policy, UVFA) 설명 드리고, HER에 대한 본 설명을 진행하도록 하겠습니다.
마지막으로, HER 논문에서 소개된 실험 환경과, 실험 결과 등을 같이 확인해 보는 시간으로, 리뷰를 마무리 짓겠습니다.

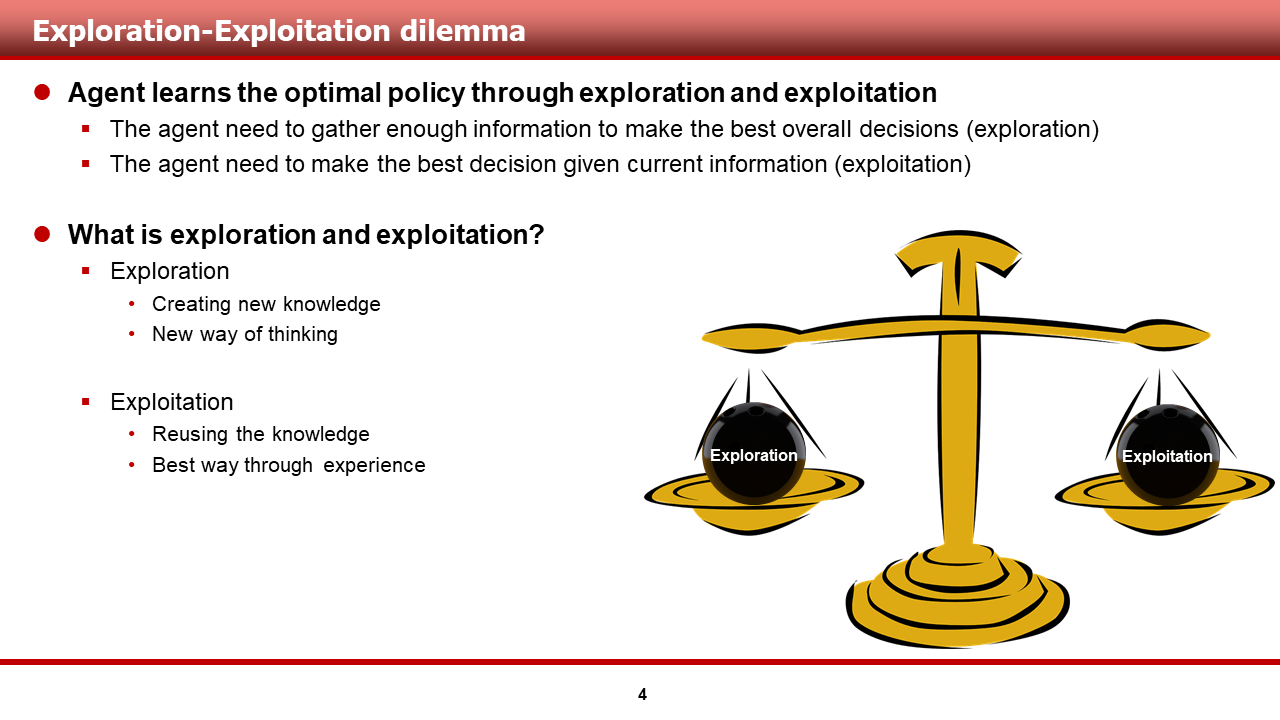
강화학습의 최종적인 목표는, 주어진 문제를 해결하기 위해 agent가 최적의 가치 함수 및 정책을 학습 하는 것입니다. 이를 위해서, agent는 탐험과 이용을 적절히 배분할 필요가 있습니다. 각각의 역할과 특성은 다음과 같습니다.
1) Agent는 탐험을 통해서, 최고의 의사선택을 내리기 위한 정보들을 모을 수 있습니다.
(1) 탐험은 새로운 지식을 만들어 내는 것과 같습니다.
(2) 탐험은 agent가 새로운 방법으로 생각할 수 있게 해줍니다.
2) Agent는 이용 혹은 착취를 통해서, 현재 주어진 정보들을 기반으로 최고의 의사선택을 내릴 수 있습니다.
(1) 이용은 이미 알고 있는 지식을 사용하는 것과 같습니다.
(2) 이용은 (탐험으로 얻은)경험을 통해 최고의 방법을 선택할 수 있게 해줍니다.
이러한 탐험과 이용의 균형을 어떻게 맞출 것이냐는 강화학습에서 가장 중요한 문제 중 하나입니다. 충분한 탐험이 수행되지 않으면, local optimal 해에 빠져버리거나, 문제를 해결 할 수 없을 수 있기 때문입니다. 이를 해결하기 위해, 기존의 Q-learning 계열 알고리즘들은 epsilon - greedy algorithm을 통해 탐험과 이용의 균형을 조절하며, PG 계열 알고리즘은 entropy term을 통해 탐험과 이용의 균형을 조절해오곤 했습니다.

앞서 말씀드린 충분한 탐험의 문제는, 특히 희소 보상(sparse reward) 환경에서 더욱 중요한 문제로 떠올랐습니다. 희소 보상 환경이란, 환경 자체가 non-zero reward signal을 굉장희 희소하게 제공하는 경우를 뜻합니다.
이러한 환경에서, non-zero reward signal을 얻기 전까지 agent의 이용(exploitation)은 크게 의미 없는 행동이 되버리며, 결국 탐험만을 통해서 non-zero signal을 얻는 것이 필요한, 탐험이 굉장히 어려운(Hard explora tion) 문제가 되어버립니다.
이 장에서 저는, 이해를 돕기 위해, 유명한 sparse reward environment의 예시를 두 가지 소개해 드리도록 하겠습니다.
(1) 몬테수마의 복수(Montezuma's revenge)
첫 번째는, ALE 환경에서 학습 가능한 몬테수마의 복수 게임입니다. sparse reward 문제로 가장 유명한 환경이며,그림의 캐릭터가 이미지만을 보고 사다리를 내려가서, 해골을 뛰어넘고, 다시 사다리를 올라가서 키를 얻어야지만 보상이 발생합니다.... 유명한 DQN, DDQN 등은 이 문제를 해결하지 못 했으며, SIL, NGU 등 탐험을 고려한 알고리즘이 나온 후에야 이 문제를 해결할 수 있었습니다.
(2) FetchPush
두 번째는, OpenAI에서 goal-based task를 학습하기 위해 제작한 gym Robotics 환경 중 하나인 FetchPush입니다. 이 환경에서 agent는 검정색의 puck을 밀어 빨간색의 공을 밀어내야 하며, reward는 말씀드린 task를 성공적으로 수행했을 때만 발생합니다. 하지만, 이 환경의 경우 reward level을 조절할 수 있으며, 사용자의 의도에 따라 dense reward를 제공하기도 합니다.
(소개해 드리고자 하는 HER은 바로 이 문제를 잘 해결 하였으며, FetchPush 뿐만 아니라 gym Robotics 환경의 여러 문제를 sparse rewrad setting으로 해결해 낸 알고리즘입니다.)

이러한 sparse reard 환경을 해결하기 위한 접근들은 굉장히 많지만, 이 장에서는 몇몇 개념에 대한 소개와, 몬테수마 복수를 예시로 든 설명을 드리고자 합니다.
(1) Reward shaping
먼저, 성공, 실패에 따라서만 제공되는 reward이외에도, 문제 해결에 도움이 되는 행동을 권장하는 방향으로 reward engineering(혹은 reward shaping)을 수행하는 것입니다. 이 방법의 경우, 해결하고자 하는 문제의 domain knowledge가 요구된다는 어려움이 존재합니다.
이러한 접근법을 몬테수마의 복수를 예로 들어 설명드리면, 사다리를 내려갈때 (+1), 해골에게 죽었을 때(-1) 등등 으로 보상을 설계하여 환경에서 주도록 하는 것입니다.
(2) Learning from demonstration
두 번째로, 사람 혹은 기존의 제어기등으로 부터 demonstration sample을 얻은 후, 그 sample과 탐험을 통해 얻는 sample 모두로 학습을 수행하는 접근 방법이 존재합니다. 이 방법의 경우, reward shaping을 해주지 않아도 된다는 장점이 있지만, 충분한 demonstration을 얻는 과정에서 어려움이 존재할 수 있습니다.
이러한 접근법을 몬테수마의 복수를 예로 들어 설명드리면, 고수인 사람이 플레이한 게임의 trajectory를 replay buffer에 저장한 뒤, 이를 학습에 직접적으로 이용하는 것입니다. (DQfD, DDPGfD 등의 알고리즘)
(3) Curiosity-driven exploration
세 번째로, 호기심 기반의 탐험을 통해 agent가 충분한 탐험을 할 수 있게 해주는 접근 방법이 있습니다. 이는 새로운 상태와 행동을 agent가 마주칠 경우, 내적 동기 보상을 발생시키는 방법으로 구현되며, 이 방법의 경우도 reward shaping을 해주지 않아도 된다는 장점이 있습니다.
이러한 접근법을 몬테수마의 복수를 예로 들어 설명드리면 목표인 키를 얻기 위해, 호기심을 가지고 적극적으로, 가보지 않은 장소로 가거나, 해보지 않은 행동 들을 하는 것입니다.
(4) HER
이번 리뷰에서 다루는 HER입니다. HER에서는 agent가 goal에 도착해 non-zero reward signal을 발생시키는 것에 실패 하더라도, 실패한 trajectory로부터 pseudo reward를 발생시키는 방법 통해, agent가 결국 goal에 도착할 수 있도록 했습니다.
이러한 접근법을 몬테수마의 복수를 예로 들어 설명드리면, 해골의 움직임을 점프를 통해 피하진 못 했지만, 어쨌든 해골 앞까지는 이동했다는 것을 학습하며, 이러한 시도를 반복해 숙련도를 높여가는 것입니다.
(1)을 제외한 (2~4)는 사람이 학습하는 방법과 비슷한 방법이죠? 강화학습이 수치 계산적으로 발전하는 것도 멋지고, 새로운 신경망을 적용하여 발전하는것도 멋질 수 있지만, 가장 재미있다고 느껴질 때는 역시나 이런 사람의 학습 방법을 적용할 때가 아닌가 싶습니다. ^^
서론이 너무 길어진 느낌이 있네요ㅠㅠ 다음 슬라이드 부터는 HER에 대해 본격적으로 다루도록 하겠습니다.

그녀가 떠오르는 제목입니다.. 저만 그런게 아니겠죠?

이 장에서는, HER을 잘 이해하기 위한 배경들에 대해서 먼저 말씀드리도록 하겠습니다.
(1) On policy vs Off policy algorithms
먼저, 강화학습을 공부하다 보면 자주 마주치는 단어인 on policy, off policy의 차이 대해서 간단히 소개하겠습니다.
On-policy algorithm의 경우, agent가 학습에 사용할 sample을 얻는 behavioral policy와, 실제 학습이 수행되며 개선될 target policy가 같거나, 유사한 알고리즘들을 통칭합니다. 유명한 A2C, TRPO, PPO 등이 이러한 알고리즘군에 속합니다.
Off-policy algorithm의 경우, behavioral policy와 target policy가 같지 않아도 되는 알고리즘을 통칭합니다. 그렇기 때문에, 학습이 수행되면서 얻은 sample들을 replay buffer에 저장하여 두고두고 학습에 사용할 수 있으며, 그덕분에 sample efficiency가 on-policy algorithm에 비해 높습니다. 유명한 DQN, DDPG, SAC 등이 이러한 알고리즘군에 속합니다.
(2) Universal value function approximation (UVFA)
두 번째로, HER이 아이디어를 차용한 논문인 UVFA에 대해서 소게하겠습니다. (무려 david silver님의 논문이었습니다...)
UVFA에서는, 1) 하나의 agent가 여러 goal에 대해서 학습 할 수 있도록, 가치함수를 goal 별로 따로 계산 했습니다. 뿐만 아니라, goal 별로 reward function을 따로 계산하였으며, 이를 pseudo reward Rg라고 정의하였습니다.
또한, 2) 이를 조건부 확률 등의 개념을 차용하는 것이 아니라. 단순히 state와 goal을 concatenate한 것을 가치함수의 입력으로 넣어주는 방식을 제안했습니다. 높은 성능의 approximator(NN 등)라면, 이를 잘 분간해 낼 것이라는 기대를 가지고 실험을 수행했으며, 좋은 결과를 얻었습니다.
HER은 replay buffer와 관련있는 알고리즘이다 보니 DQN, DDPG등의 off-policy algorithm에만 적용 할 수 있는 알고리즘이며, 별도의 언급은 없지만, UVFA에서 제시한 pseudo reward개념을 통해 실패한 trajectory의 achieved goal을 desired goal로 치환하여 reward signal을 발생시키는 접근법을 취하고 있습니다. 자세한 내용은 이어서 설명하도록 하겠습니다.

본격적인 방법론 설명에 앞서, 저자들이 제안한 algorithm에 대해 어떤 평을 했는지에 대해 소개해드리겠습니다.
(1) Goal g를 달성하지 못한 임의의 실패한 trajectory를 해당 trajectory의 종단 상태 등에 다다르는 정보를 줄 수 있는 trajectory로써 재 평가하여 학습에 이용하는, 마치 사람처럼 학습하는 컨셉을 제시
(2) Sparse reward 환경에서 샘플 효율적인 학습이 가능한 알고리즘이라는 것을 실험을 통해 증명
(3) 동일한 환경에서 dense reward보다 sparse reward setting에서 더 좋은 성능을 보임으로써, 복잡한 reward engineering이 필요 없을 수 있음을 보여줌
(4) 기존의 off-policy algorithm과 결합하는 것이 매우 쉽다는 것을 강조
다음 슬라이드 부터는, 이러한 평가를 내린 HER 알고리즘에 대해 본격적으로 다루도록 하겠습니다.

먼저, HER의 의사 코드 입니다. 임의의 off-policy algorithm이 주어져 있다고 가정하며, 뒤이어 설명드릴 HER의 strategy S와, sparse reward function R을 정의해줍니다.
이후 에피소드 별로 step을 밟는 과정에서는, 정책을 통해 행동을 고르는 과정에서, 정책의 입력으로 state가 아닌 state와 goal을 concatenate한 s||g를 활용해주고 있습니다. 이는 UVFA에서 차용한 개념으로 보입니다.
그 후, 학습을 수행하기 전, replay buffer에서 transition을 sampling 하는 것과 함께, strategy S에 따라 additional goal g'을 sampling 하는 모습을 볼 수 있습니다. 이는, 문제를 관통하는 original goal g가 있긴 하지만, g에 도달하지 못한 trajectory의 경우 rg는 항상 near-zero reward일 것이기 때문에, additinal goal g'에 대해 새로 non-zero reward signal을 계산하기 위함입니다.
그리하여, additional goal g'에 대해 발생한 non-zero reward signal rg'과 s||g'으로 치환된 sample을 통해 agent는 학습을 수행합니다. 이러한 과정을 통해 original goal g에 도달하는 것을 실패한 trajectory로 부터도 정책이 개선될 수 있는 것입니다.
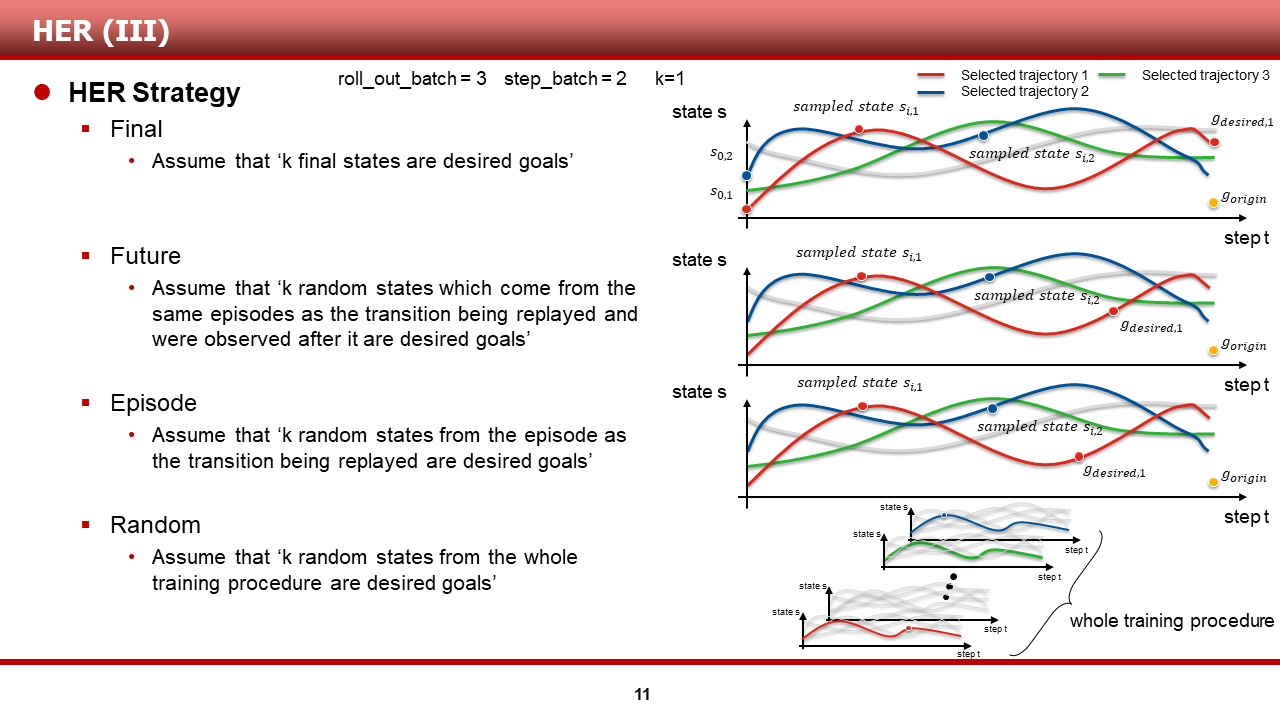
다음 슬라이드 부터는, HER에서 additional goal을 sampling할 때 사용한 strategy(전략) S 에 대해 설명드리겠습니다.

HER의 저자들은, additional goal을 sampling 하는 방법에 여러가지 전략이 있을 수 있다는 것을 시인하며, 자신들이 고안한 4가지의 전략에 대해서 설명을 수행했습니다. 논문에는 너무 간단하게 설명이 되어 있어, 실제 구현된 code를 참고하여 전략별로 설명을 재구성 해보았습니다.
(1) Final
가장 직관적으로 이해가 쉬운 전략입니다. 임의의 3개(roll_out_batch)의 trajectory를 선택 후, 2개(step_batch)의 sample transition들을 학습에 사용한다고 했을 때, Final 전략 사용시 1개(replay_k)의 goal을 실제 그 trajectory의 종단 상태 s_T로 재평가합니다. 그리하여, 첫 번째 그림의 sampled state s의 경우, s||g의 g를 g_origin이 아닌 g_desired,1로 치환 했음을 알 수있으며, 이 trajectory에서 여러 개의 sample transition을 선택할 경우, non-zero reward가 발생할 수 있습니다.
(2) Future
가장 직관적으로 이해하기 어려운 전략입니다.. 선택한 trajectory의 종단 상태를 goal로 사용하는 Final 전략과 달리, 선택한 trajectory의 선택된 sampled state를 기준으로, 임의의 step time 이후 도달하는 state를 g_origin 대신 goal로써 사용합니다. 그리하여, Final의 g_desired,1과 위치를 비교해 보면 조금 더 앞쪽에 goal이 위치함을 알 수 있습니다.
(3) Episode
Future와 비슷한 전략입니다. Episode 전략의 경우, 선택한 trajectory의 선택된 sampled state의 위치와 상관없이, 그 trajectory 내부의 임의의 state를 goal로써 사용합니다.
(4) Random
말 그대로 Random 전략입니다. sample transition을 얻기 위한 trajectory와 관계 없는, 전체 훈련 과정 중에 거쳐온 state중 임의의 state를 goal로써 사용합니다.
기존의 논문에 서술된 내용이 조금 부족하여, 열심히 자료를 만들어 봤지만... 이럼에도 완벽한 설명은 힘든 것 같습니다. 실제로 구현 및 사용을 원하시는 분들의 경우에는 원 저자들의 코드를 보는 것이 가장 좋을 것 같다는 생각이 듭니다. 운이 좋게도 원 저자들이 OpenAI이기 때문에, 밑의 링크인 stable baseline에 깔끔한 구현체가 존재합니다.
https://github.com/openai/baselines
openai/baselines
OpenAI Baselines: high-quality implementations of reinforcement learning algorithms - openai/baselines
github.com
저자들은 이러한 goal sampling 전략에 따른 HER의 성능을 테스트하는 것을 포함하여, 여러 실험을 수행 하였으며, 다음 슬라이드부터는 실험 결과에 대해 설명 드리도록 하겠습니다.

먼저, 저자들이 실험을 수행한 환경에 대해 간단히 소개해드리고 넘어가도록 하겠습니다. 저자들은, 앞서 도입부에서 설명드렸던 FetchPush을 포함하여 gym robotics의 세개의 환경을 사용했습니다. 각각의 환경에 대한 소개는 슬라이드에 기술되어 있는 문장을 참고하시면 될 것 같습니다.

각각의 환경에서의 MDP formulation은 다음과 같습니다. 특이한 점은, Reward의 level을 sparse reward, shaped reward로 선택할 수 있다는 것이며, HER 사용시 strategy S 또한 선택하도록 되어 있습니다.

이 장에서는, 실험 결과를 설명드리도록 하겠습니다. 저자들은 논문에서 크게 다섯 가지의 실험 결과를 제공하고 있으며, 이 장에서는 먼저 두 가지 결과에 대해 공유드리겠습니다.
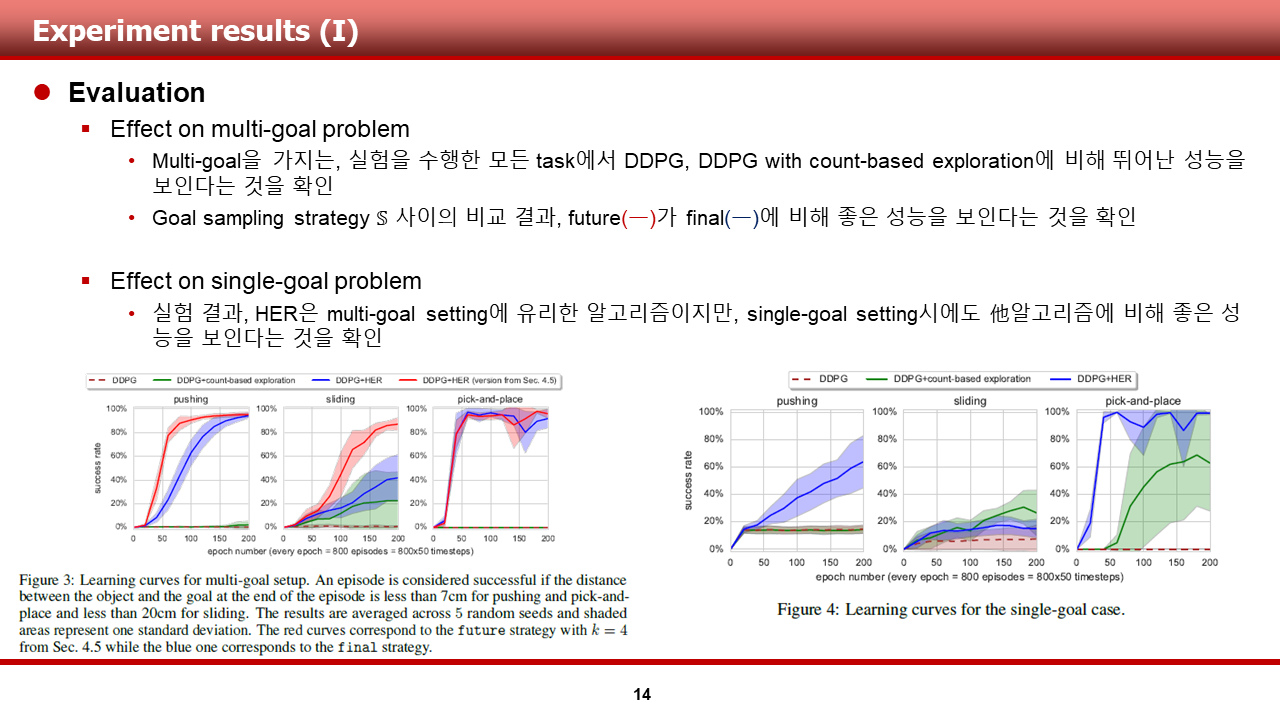
(1) Multi-goal 문제에 대해, HER 적용 유무에 따른 성능 비교
하단 왼쪽의 그래프는 multi-goal 문제를 학습했을 때의 success rate를 보여줍니다. HER을 적용한 빨간색과 파란색 그래프의 경우, 모든 문제에 대해 상당한 성능을 보이고 있지만, HER이 적용되지 않은 DDPG와, count-based exploration 기법이 추가된 DDPG의 경우에는 그에 미치지 못하는 성능을 보인다는 것을 알 수 있습니다.
(2) Single-goal 문제에 대해, HER 적용 유무에 따른 성능 비교
하단 오른쪽의 그래프는 보다 간단한, single-goal 문제를 학습했을 때의 success rate를 보여줍니다. HER을 적용한 파란색 그래프의 경우, 기존의 multi-goal 문제에서 보였던 압도적인 성능을 보여주지는 못 하는 것을 알 수 있습니다. UFVA 특성 상 unseen goal에 유리하도록 설계가 되어 있는데, 그 장점이 single-goal 문제에선 퇴색됬던 것 같습니다. 하지만, pushing과 pick-and-place 문제에서는 DDPG, DDPG with count-based exploration보다 뛰어난 성능을 보인다는 것을 알 수 있었습니다.

이 장에서는, 나머지 세 가지 중 두 가지의 실험 결과에 대해서 공유드릴 수 있도록 하겠습니다.
(남은 하나는, sparse reward와 dense reward setting시 sparse reward 환경에서 HER이 더 좋은 결과를 냈다는 결과입니다. 완벽한 이해가 되지 않아서, 스킵 하였으며, 궁금하신 분들은 밑의 원 저자의 논문을 참고해주시길 바랍니다.)
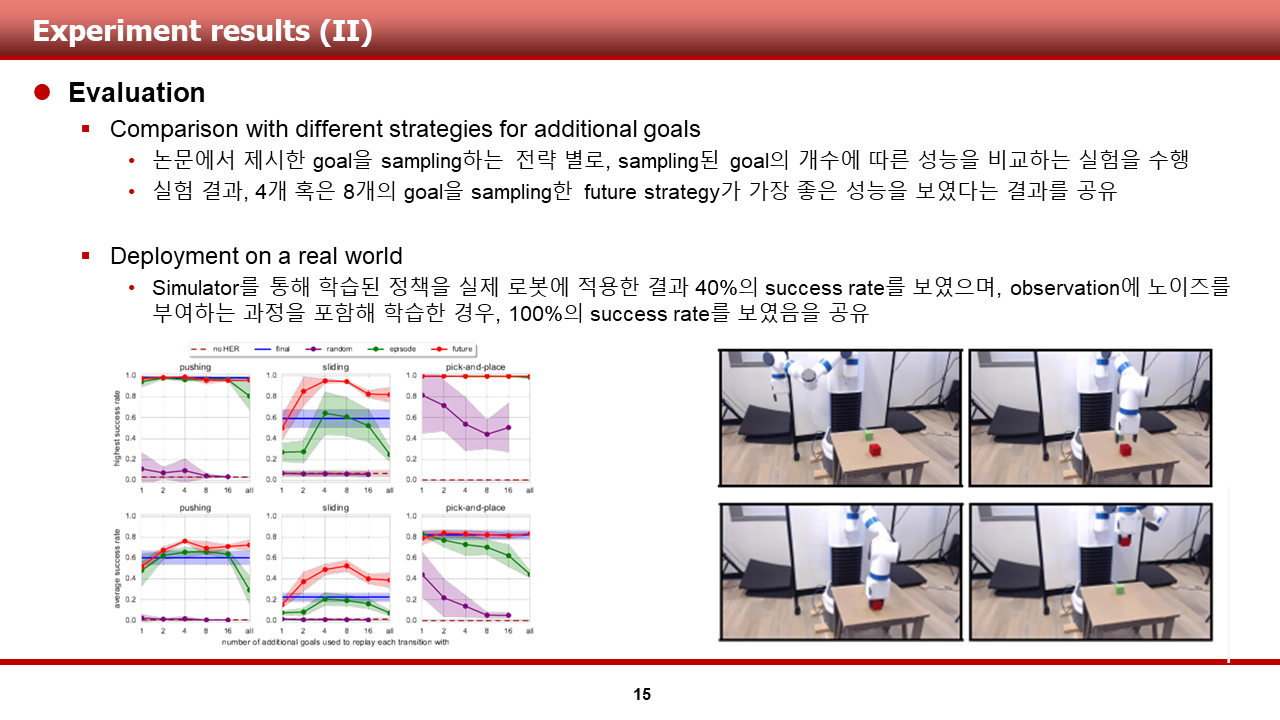
(3) Strategy S와, additional goal의 개수인 replay_k에 따른 HER의 성능 비교
앞서 방법론 쪽에서 설명드렸던 Strategy S와, sampling된 additional goal의 개수에 따른 성능을 세 개의 환경에서 비교한 실험입니다. 하단 왼쪽 그림이 실험의 결과 그래프 이며, 그래프의 x축은 additional goal의 개수를 의미하며, 그래프의 색과 형상에 따라 noHER과 4개의 전략을 적용한 HER들의 성능을 확인할 수 있습니다. 결론만 말씀 드리면, 4개 혹은 8개의 goal을 sampling한 future strategy가 가장 좋은 성능을 보였다고 합니다.
* 하지만, 이 문제의 경우, time step이 50으로 길지 않은 episode로 알고 있기 때문에, 이 replay_k의 개수는 문제별로 크게 다르지 않을까 하는 생각이 듭니다.
(4) Deployment on a real world
역시나 OpenAI의 클래스에 맞게, 저자들은 시뮬레이터를 통해 학습된 정책을 실제 로봇에 적용하는 실험을 추가적으로 수행하였습니다. 그리하여, 바로 적용한 정책의 경우에는 시뮬레이터에서 얻은 결과에 비해 낮은, 40%의 success rate를 보였다는 것과, 학습 시 observation에 noise를 부여하는 과정을 포함해 학습한 정책의 경우에는 시뮬레이터에서 얻은 결과와 동일한, 100%의 success rate를 보였다는 결과를 공유했습니다.
논문을 리뷰하다 보니, 코드 분석에 꽤나 많은 시간을 소모했는데, 그 시간이 아까워서 HER도 구현해야 하나 고민이 많습니다. 어찌 되었든... 오랜만에 글을 쓰게 되었는데, 길고 긴 글을 읽어주신 독자분께 진심으로 감사를 표합니다.
수학적인 난이도가 높았던 논문은 아니었던 것 같아서, 쭉 읽으시면 저와 동일한 이해를 얻지 않을까 싶습니다. 하지만, 이해가 어려운 점이 있으셨다면, 댓글을 통해 질문을 주시면 성의껏 답변을 해 드리도록 하겠습니다.
논문의 링크와, 전체 슬라이드는 밑에 준비되어 있습니다.
https://arxiv.org/abs/1707.01495
Hindsight Experience Replay
Dealing with sparse rewards is one of the biggest challenges in Reinforcement Learning (RL). We present a novel technique called Hindsight Experience Replay which allows sample-efficient learning from rewards which are sparse and binary and therefore avoid
arxiv.org