이 글에서는, 강화학습 논문 리뷰 다섯 번째 연재글에서 리뷰했던 MADDPG의 성능을 확인하기 위해, 기존의 TD3, DDPG와 비교한 결과를 공유하려 합니다.
구현은 RL_Korea의 옥찬호님이 주도하시는 RL 논문 리뷰 스터디 (4기)에 참여하며 수행하였습니다. 저 뿐만 아니라, 다른 분들의 논문 리뷰 자료들까지 포함되어 있는 깃허브 주소는 다음과 같습니다. github.com/utilForever/rl-paper-study
utilForever/rl-paper-study
Reinforcement Learning paper review study. Contribute to utilForever/rl-paper-study development by creating an account on GitHub.
github.com
그럼 본격적인 리뷰 시작하겠습니다!

논문의 제목은 다시 보아도 직관적입니다. 협력적이거나, 경쟁적인 행위들이 섞여있는 혼합 환경에서의 Multi-agent actor-critic 알고리즘에 대해 다룰 것만 같은 이 느낌.. 넘어 가겠습니다!

목차는 다음과 같습니다.
이번 리뷰에서는, 기존의 기법인 DDPG, TD3와 MADDPG 모두 간단한 설명만을 드린 뒤, 적용한 환경에 대한 간단한 소개를, 마지막으로 각 기법들의 시뮬레이션 결과를 공유하고자 합니다.

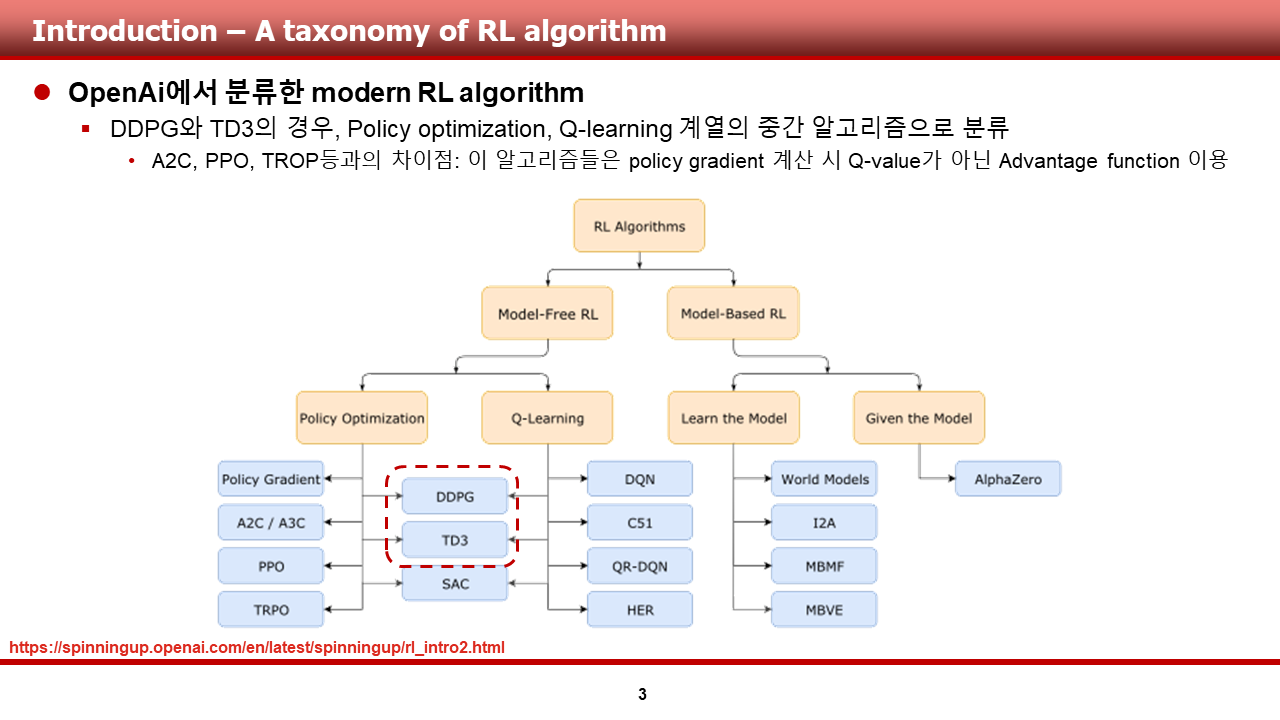
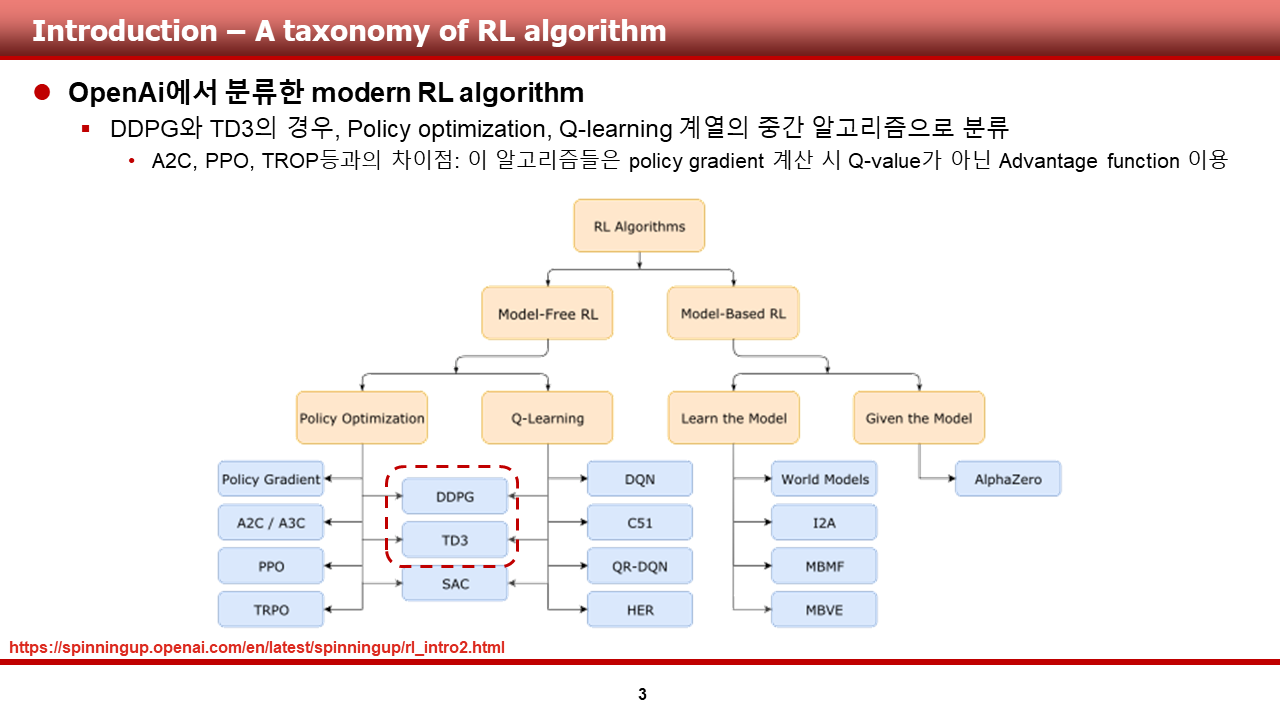
방법론입니다. 기존의 기법인 DDPG, TD3, 그리고 MADDPG에 대해 한장의 슬라이드로 슥슥 넘어가겠습니다.

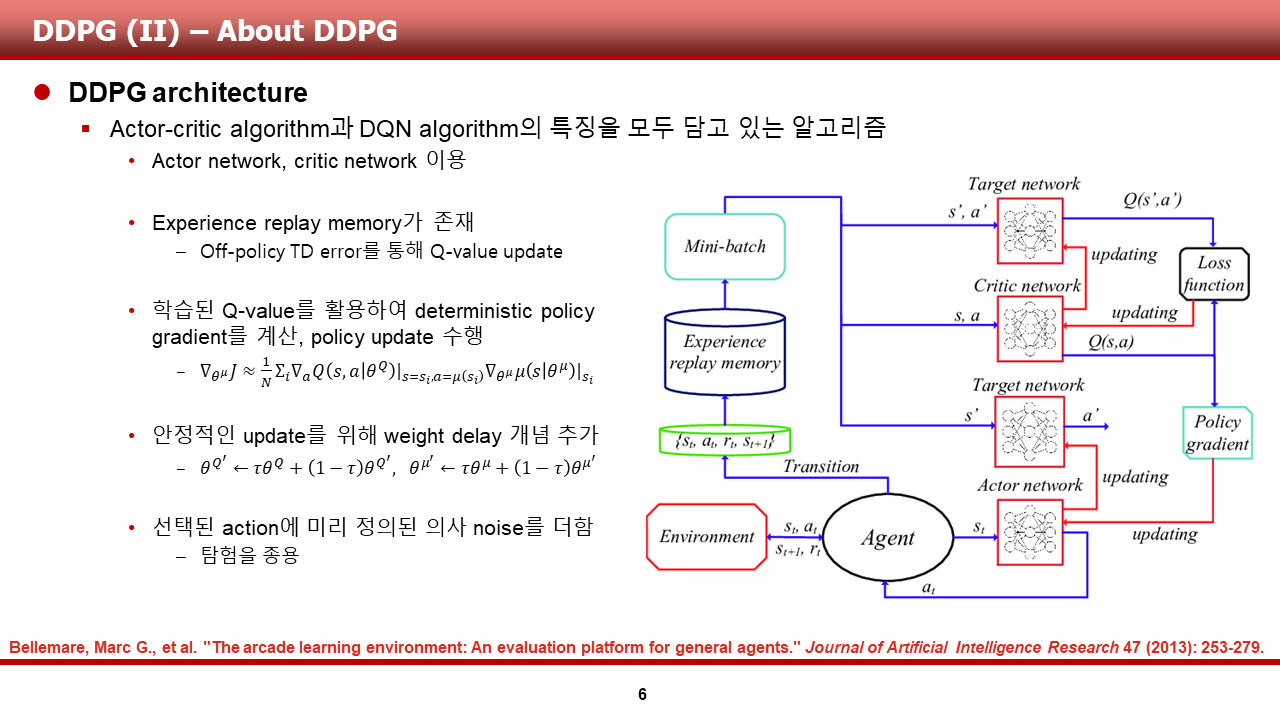
먼저, DDPG 입니다. DDPG의 경우, 제어 등의 continuous control problem에서 좋은 성능을 보였다고 알려져 있는 알고리즘입니다.
이 알고리즘의 경우, DQN의 성공 이후 DQN의 여러 특성들을 기존의 DPG 알고리즘에 차용해서 좋은 성능을 보여주었습니다.
1) Experience replay
DQN에서 크게 성공을 거둔 이유 중 하나인, 경험 리플레이를 사용
2) Delayed weight update of target network
DQN과 같이 n step 고정시키는 방식이 아닌, first order delay를 통해 매 스텝 delayed 업데이트
3) Deep neural network
Actor network와 Critic network를 모두 심층 신경망으로 구성
DDPG의 전신이 되는 DPG 알고리즘의 경우는 다음과 같이 이루어져 있습니다.
1) Deterministic policy
특정 상태에 따라, action이 확정적으로 정해지는 정책
2) Objective function J
theta로 파라미터화 된 정책의, theta에 따른 목적함수 J를 정의
3) Deterministic policy gradient
replay buffer로부터 sample을 꺼내와 업데이트 해도 수학적으로 문제가 없는, policy gradient 식을 정의

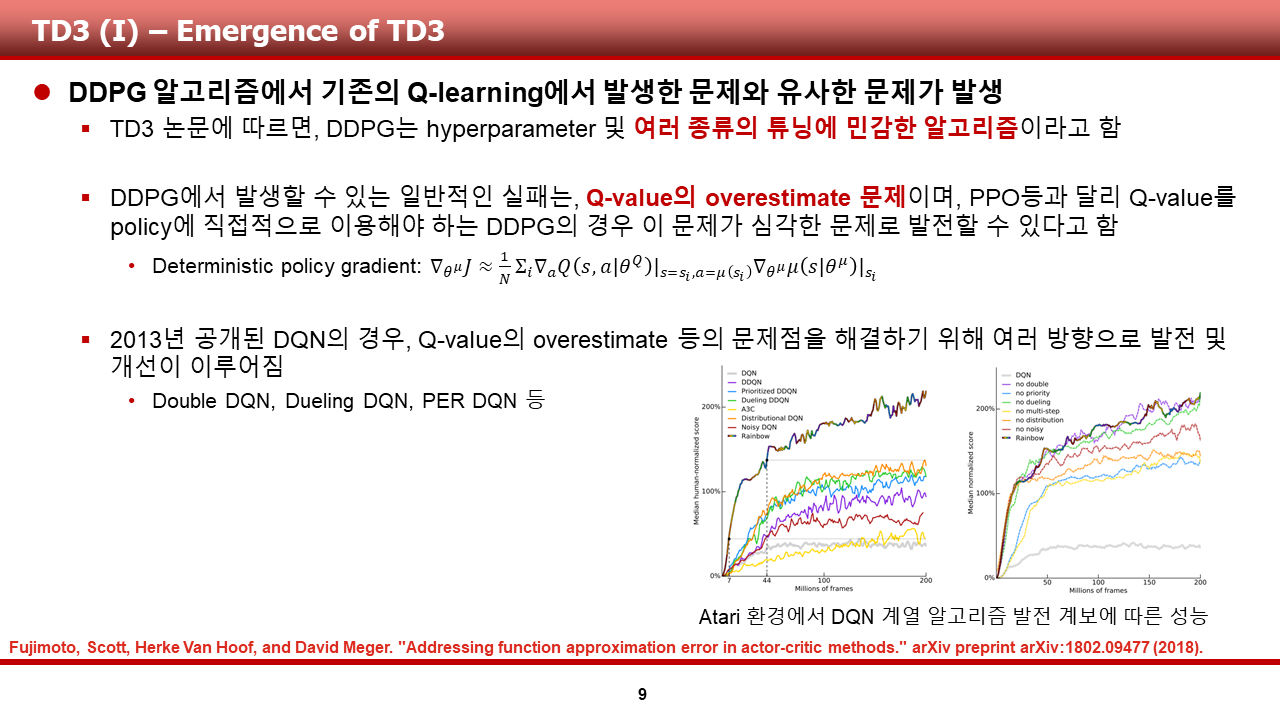
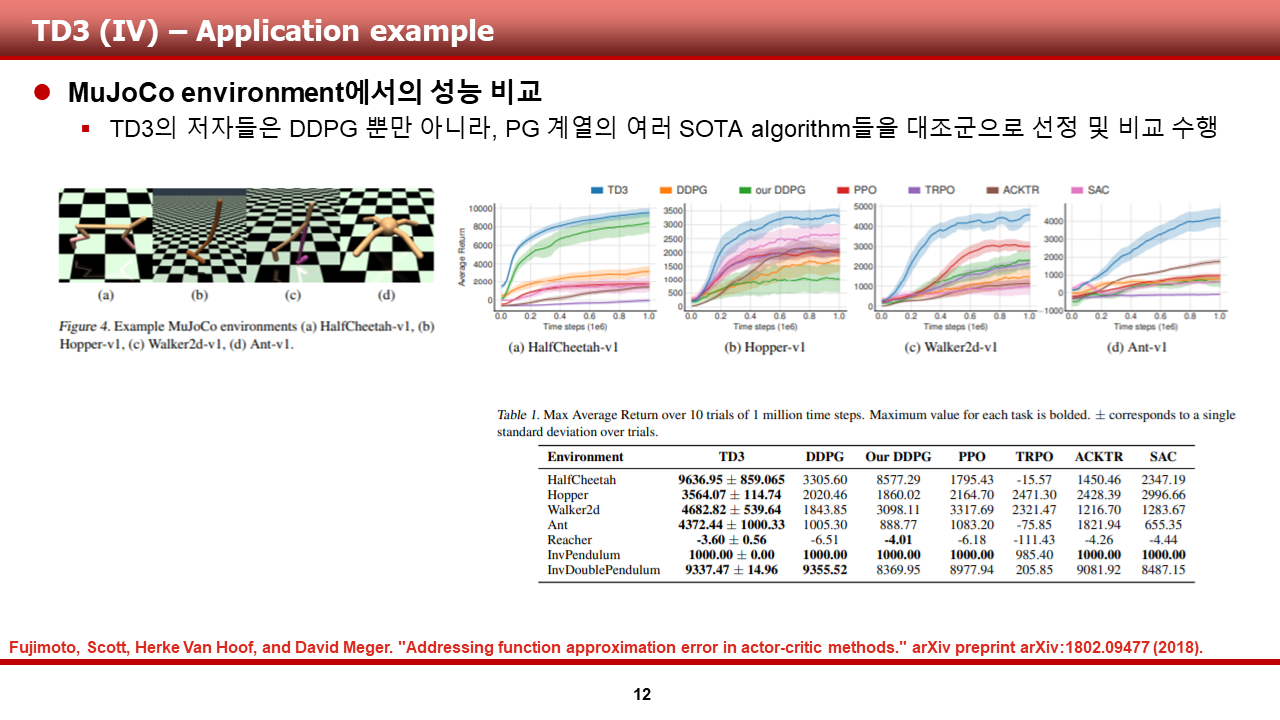
다음은, TD3 입니다. TD3의 경우, DDPG가 쓰이는 여러 도메인에서 DDPG에 비해 안정적인 수렴 성능을 보여준다고 알려져 있습니다.
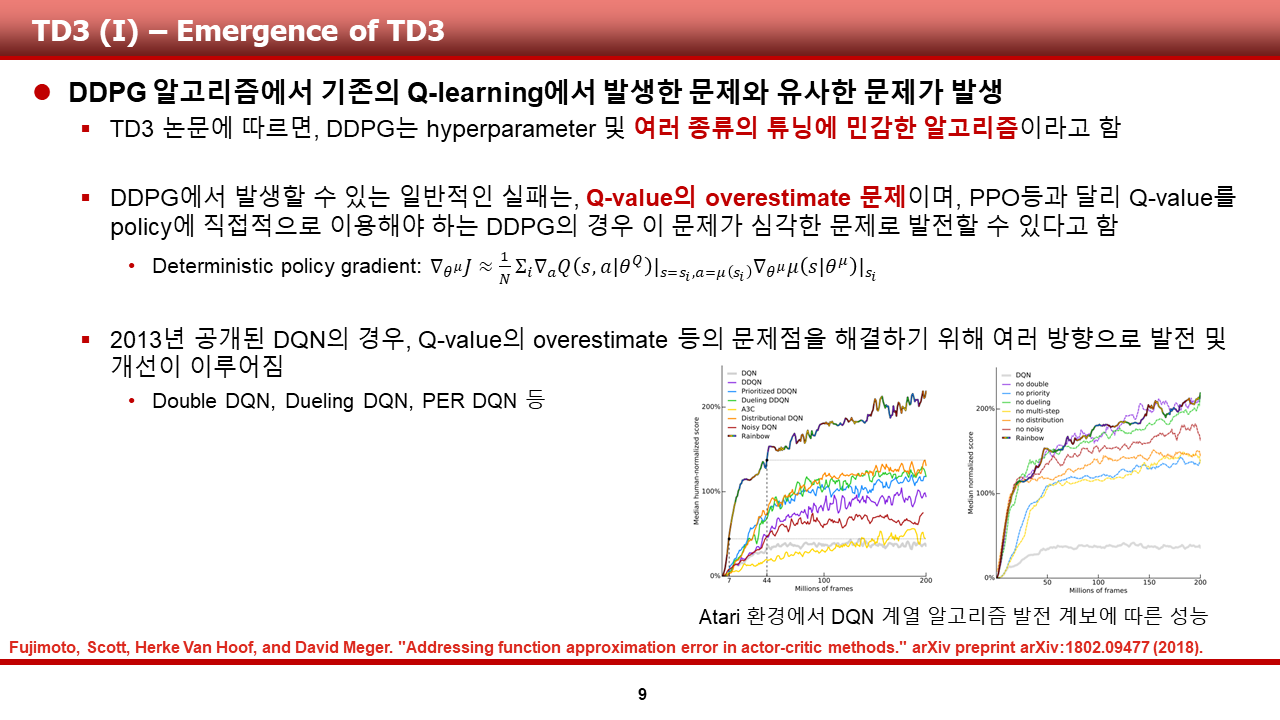
이 알고리즘의 경우, DDPG에서 발생했던 여러 문제점 중 하나인 Q value의 overestimate 문제를 완화시킬 수 있는 여러 트릭을 사용함으로써 DDPG의 성능을 개선한 알고리즘으로 알려져 있습니다. 그 트릭들은 다음과 같습니다.
1) Clipped double Q-learning
2) Delayed policy update
TD3의 자세한 내용은 제 블로그의 TD3 리뷰 혹은 제가 속해 있는 팀 블로그의 글을 봐주시면 감사할 것 같습니다.
https://seungeonbaek.tistory.com/14
Paper review of RL (4) Addressing Function Approximation Error in Actor-Critic Methods (TD3)
강화학습 논문 리뷰 연재 네번째입니다. 이번 논문 리뷰는, 기존의 DeepMind control suite, 상용 동역학 시뮬레이션 프로그램 등의 continuous control 환경에서 좋은 성과를 거둬온 DDPG(Deep Deterministic Pol..
seungeonbaek.tistory.com
https://ropiens.tistory.com/89
TD3 리뷰 : Addressing Function Approximation Error in Actor-Critic Methods
editor, Junyeob Baek Robotics Software Engineer /RL, Motion Planning and Control, SLAM, Vision - 해당 글은 기존 markdown형식으로 적어오던 리뷰 글을 블로그형식으로 다듬고 재구성한 글입니다 - ori..
ropiens.tistory.com

유사한 이유로, MADDPG도 이번 글에선 생략하고 넘어가도록 하겠습니다.

시뮬레이션 결과 단락은, 학습이 수행될 환경, 학습 결과의 간단한 분석으로 구성하였습니다.

먼저, MADDPG를 구현할 환경으로써 저는 SISL환경 내의 multi-walker를 선정하였습니다. 이 환경의 경우, n개의 bipedal walker가 위에 짊어진 꾸러미를 떨어뜨리지 않은 채로 다 같이 전진하는 것을 목적으로 하고 있습니다.
이 환경의 인수들은 다음과 같습니다.
1) walker의 대수 (default 3 대)
2) 위치/자세의 noise 정도 (default 0.5)
3) episode 내 max_cycle (default 500 step)
4) rewards
전진 시 10 점, 넘어질 시 -10 점, 꾸러미를 떨어 뜨릴시 -100점
(-100 점이라니, 협업을 하지 않을 경우 굉장히 가혹한 페널티가 존재하는 무시무시한 환경입니다..)
이 환경의 행동 / 관측 정보의 요약은 다음과 같습니다.
1) Action: 두 다리에 존재하는 두 joint에 가해지는 외력
2) Observation: 에이전트의 각 축 별 속도, 각, 센서 관측치, 주변 객체들의 상대 위치 .... 등등
기존의 bipedal walker 문제만 하더라도, 상당히 난이도 있는 continouos control 문제인 것으로 알고 있는데, multi-agent간의 협업을 연구하기 위해 스탠포드가 우물에 독을 푼 것이 아닌가 하는 생각이 들게끔 하는 환경입니다.

앞서 설명드린 환경에서의 학습 성능은 다음과 같습니다. 총 500 episode 정도 학습을 수행하였으며, 결과만 말씀드리면, MADDPG를 제외하고 두 알고리즘은 학습이 되지 않았습니다.
그 이유를 저는 다음과 같이 분석하였습니다.
1) DDPG의 경우: reward 편차가 큰 이러한 환경에서, 개별 agent만을 제어할 수 있는 알고리즘이기 때문에 학습에 어려움을 겪은 것으로 사료됩니다.
2) TD3의 경우: reward 편차가 크더라도, DDPG보다 안정적인 학습이 가능한 TD3이지만, 개별 agent만을 제어할 수 있다는 한계점으로 인해, 모든 agent가 500 step 동안 가만히 있다가 끝나는 방식으로 학습이 수행 되었습니다.
3) MADDPG의 경우: 모든 agent의 정보를 받아서 학습을 수행할 수 있으므로, 50 episode 이내로 pacakge를 떨어뜨리지 않는 채로 3 대의 agent가 협력하여 전진하는 것을 확인할 수 있었습니다. (reward > 0)
사실은 더 많은 step을, 더 많은 agent에 대해 1M, 2M 만큼의 episode를 학습 시켜보면서 결과를 봐야하지만, 노트북이 울부짖는 소리에 마음이 아파 default setting을 해결하는 것 정도에서 학습을 마무리 짓고자 합니다.
논문 리뷰를 하고 시간이 꽤나 지난 후에 구현 및 결과 분석 글을 쓰니 회사일이 바빴던 건지 제가 게을렀던 건지 아무튼 성찰의 시간을 가져야 할 것 같다는 생각이 듭니다. 오랜만에, 두서 없이 쓴 글이지만, 읽어 주셨다면 정말 감사합니다!!
논문의 링크와, 전체 슬라이드는 생략하도록 하겠습니다.