오랜만에 강화학습 논문 리뷰를 하게 되었습니다.
오늘 준비한 논문은 강화학습에서 많이 사용되는 환경, 최근에 구글에서 공개한 환경과 관련된 논문들입니다.
각각 논문의 제목은 다음과 같습니다.
1) The Arcade Learning Environment: An Evaluation Platform for General Agetns
2) DeepMind Lab
3) Google Research Football: A Novel Reinforcement Learning Environment
그럼, 본격적인 리뷰 시작하겠습니다!

이번에 리뷰를 하게된 1번 논문(ALE)의 경우, DeepMind에서 제공한, 유명한 Atrai 2600 game을 이용한 환경입니다. 얼마전 Agent57이 정복한 환경이기도 하고, 입문자와 중급자들에게는 정말 친숙한 환경이 아닐수가 없습니다.
2번 논문의 경우 또한 DeepMind에서 제공한 Quake III 게임을 이용한 환경입니다. 3D 환경이며, partial observable한 환경을 제공하는 것으로 잘 알려져 있습니다.
3번 논문의 경우, 2020년 Google 에서 제공한 환경으로, multi-agent 강화학습과 self-play 훈련 시스템을 적용해보는 것을 주 목적으로 만들어진 환경입니다.
이러한 환경들은 각기 다른 목적을 가지고 제공 되고 있으며, 연구자들은 환경을 직접 만드는 것이 여의치 않다면, 이러한 환경들 중 자신의 목적에 맞는 환경을 정하여 강화학습 알고리즘을 테스트해 볼 수 있어야 할 것 같습니다.

목차는 다음과 같습니다.
가장 먼저, ALE 논문에서 강조하는 domain-independent agent에 관련한 내용에 대한 설명과, 강화학습 알고리즘을 설계하는데에 있어 Benchmark 환경의 중요성이 무엇인지에 대해 도입부에서 설명드리려 합니다.
그 후, 본론에서는 ALE, DeepLab, GRF 이 3개의 환경에 대해 각각 설명을 드리는 것으로 자료를 준비했습니다. 각 환경들을 비교하는 것도 물론 의미가 있겠지만, 목적 자체가 많이 다른 환경들이기 때문에 자료에 추가하지는 않았습니다.
이번 리뷰에서 소개드릴 3개의 강화학습 환경과 관련된 논문들 중, 가장 먼저 작성된 논문인 ALE에서는 AI의 장기적이고 지속적인 목표가 domain에 대한 구체적인 지식이 없이도 다양한 분야에서 다양한 task를 수행할 수 있는 agent을 설계하는 것이라고 언급하였습니다.
이 논문에서는 이러한 agent를 domain-independent AI 혹은 general AI라고 칭하였으며, 이러한 agent를 연구하기 위해 ALE 환경을 공유하게 되었다고 했습니다. ALE는 고전 게임인 Atari 2600 game의 수 백여개의 게임을 agent를 학습하기 위한 환경으로써 제공하며, 이러한 다양한 game을 수행할 수 있는, domain-independent AI를 최종 목표로 삼는다는 설명이 되어있었습니다.
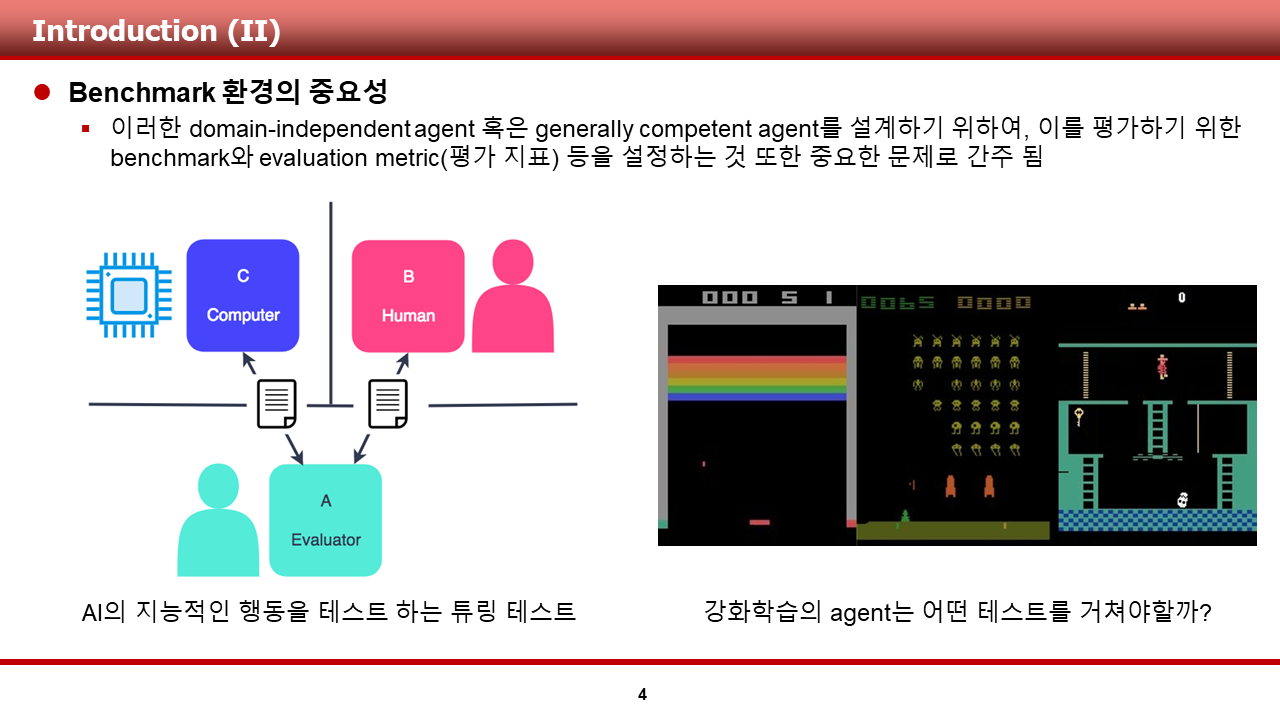
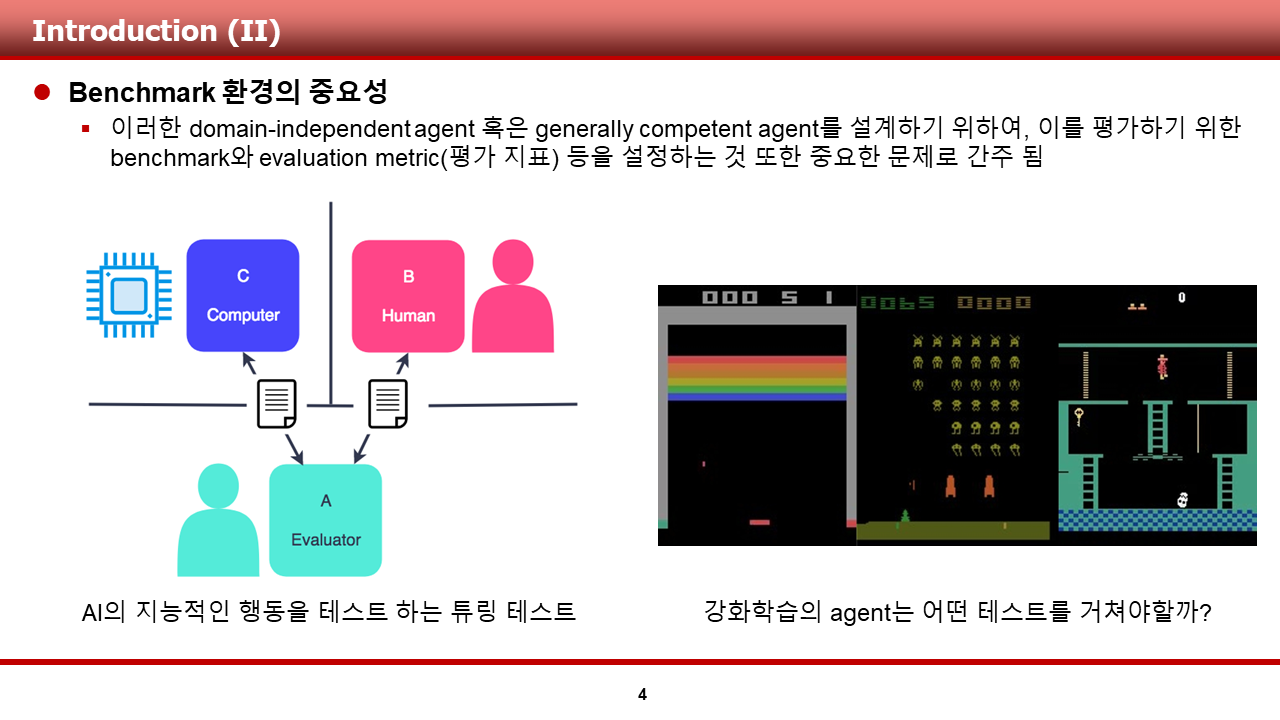
ALE가 지향하는, domain-independent agent의 설계와 같은 궁극적인 목표를 이루기 위해서는, 혹은 협소하게 바라보았을 때, 강화학습 알고리즘의 성능을 테스트 하기 위해서는, ALE에서 제공하는 것과 같은 Benchmark가 필요합니다.
저는 이번 리뷰에서 이러한 benchmark의 역할을 하는 환경들이 대표적으로 어떤 것들이 있으며, 어떤 특징이 있는지에 대해 앞으로 설명 드리고자 합니다. 그럼, 하나 하나 소개를 시작하겠습니다.

첫 번째로 설명드릴 환경은 DeepMind에서 제공한 ALE, Arcade Learning Environment 입니다. 이 환경은 2012년 논문을 통해 세상에 공개가 되었으며, 현재까지도 많이 사용되는, Atari 2600 game을 강화학습 알고리즘의 학습과 검증에 사용할 수 있는 interface를 제공 해 주었습니다.
또한, ALE 논문에서는 이 환경을 통해 다음과 같은 재미있는 컨셉의 학습/검증 방법을 제안하였습니다. 그것은, "몇 몇 게임들을 training game으로써 사용하여 agent를 학습시키고, test game으로써 다른 게임들을 사용하여 agent의 general AI competency를 시험할 수 있다!" 입니다. 이 컨셉은 실제 알고리즘 테스트를 할때 많이 사용되진 않지만, DeepMind가어떠한 철학으로 ALE 환경을 공유하였는지를 엿 볼 수 있는 문장인 것 같습니다.

이러한 ALE는 또한 다음과 같은 특징을 가지고 있습니다. 먼저, 내부 source code는 C++로 되어 있으며, 다양한 언어를 통해 상호작용이 가능하도록 설계가 되었다고 합니다. 또한, ALE 논문을 공유할 당시에는 SARSA(lambda), human performance 등의 baseline performance를 제공하여 알고리즘의 성능을 비교해 볼 수 있게끔 해주었다고 하며, 현재에는 DQN(2015)~Agent57(2020)등 더욱 많은 알고리즘들이 다양한 게임들에 대해 score등의 지표로 성능을 공유하고 있습니다.
또한, 이 논문에서는, ALE 환경을 이용하는 연구자들이 학습을 더욱 수월하게 진행할 수 있도록, ALE에서 어떤 feature를 통해 학습하는 것이 성능이 좋았는지에 대한 case study를 수행하여 그 결과를 공유해주고 있습니다. 저는 저자들이 어떠한 case를 수행했는지에 대해 간단히 설명드리겠습니다.
1) 게임 화면의 색 정보만을 feature로 사용하는 basic
2) 주변의 색 정보 또한 고려한 BASS
3) 움직이는 object만을 feature로 사용한 DISCO
4) RAM상의 rwa data를 직접 이용하는 RAM
DeepMind는 이렇듯 학습의 전 단계에서 여러 feature 추출 방법을 실험하였으며, 오른쪽 표로 각각에 대한 결과를 보여주고 있습니다.

두 번째로 설명드릴 환경은 DeepMind에서 제공한 DeepMindLab이라고 하는 환경입니다. 이 환경은 2016년 논문을 통해 세상에 공개가 되었으며, Quake III 라고 하는, 3D game을 강화학습 알고리즘의 학습과 검증에 사용할 수 있는 interface를 제공해 주었습니다.
이 환경은, 2D 고전 게임인 Atari game과 비교하면 매우 복잡하고, 부분적으로 관측가능하며, 시각적으로 다양한 환경(다양한 상태)을 agent에게 훈련 시킬 수 있는 기회를 환경을 이용하는 연구자들에게 제공해 주었습니다. 또한, Atari 2600 game을 통해 구축한 ALE와 유사하게 이번에도 기존에 존재하였던 게임 엔진을 이용해 3D game platform을 구축했다고 하며, fps를 조절하는 기능 정도를 추가적으로 제공한다고 합니다.
이러한 DeepLab 환경에서 이용자가 사용할 수 있는 observation, action 등은 다음과 같이 정의가 되어 있습니다.
1) observation의 경우에는 환경에 포함되어 있는 reward, 현재 화면의 rgbd, 객체의 velocity information 등을 agent가 받을 수 있게끔 정의가 되어있습니다.
2) action의 경우에는 그림에 표현 되어 있는 6방향의 움직임과 시선 이동, tagging(laser 발사) 등을 선택할 수 있게 정의가 되어 있습니다.

이러한 DeepLab은 또한 다음과 같은 특징을 가지고 있습니다. 내부 source code는 C로 되어 있으며, C와 python에서 이 환경을 사용할 수 있도록 API를 제공한다고 합니다.
또한, 환경을 이용하는 연구자들은, agent 학습에 사용할 수 있도록 여러 예제 게임을 4개의 난이도 별로 제공한다고 하며, 각 난이도에 대한 명칭과 자세한 설명은 PPT에 옮겨 두었기에 생략하겠습니다. 연구자들은 이러한 예제들을 이용하여 궁극적으로 Quake 게임 상에서 적을 때려잡는 괴물 agent를 학습시키기 위하여, 단계적으로 agent를 학습할 수 있는 것입니다.

마지막으로 설명드릴 환경은 DeepMind의 모회사 Google에서 제공한 Google Research Football이라고 하는 환경입니다. 이 환경은 2020년 아카이브 논문을 통해 세상에 공개가 되었으며, Multi-agent 강화학습 알고리즘의 학습과 검증에 사용할 수 있는 벤치마크 환경을 제공해 주고 있습니다.
이 환경은 비교적 최근인 2020년에 공유가 되었기 때문에, 현재 SOTA로 여겨지는 알고리즘인 PPO와, DeepMind에서 공유한 분산 강화학습 아키텍쳐, 알고리즘인 IMPALA, Ape-X DQN 등을 통해 학습한 baseline performance를 제공한다는 것 또한 눈여겨 볼만한 내용이었습니다.
또한, 논문에서 저자들이 말하는 GRF가 기존의 환경과 다른 3가지 특징은 다음과 같습니다.
1) 먼저, 기존에 사용된 환경들의 경우, 환경의 모델이 deterministic 하여, stochastic한 실제 세상을 표현하는데 한계가 있었다는 내용을 언급합니다. 또한, model의 P를 학습할 수 있는 model-based learning을 통한 학습의 가능성도 이러한 특징과 엮어 언급하고 있었습니다.
2) 두 번째로, ALE, DeepLab 등 현재 많이 사용되고 있는 환경들과 달리, GRF는 open source로써 내부 코드를 공개한다는 점을 언급 및 강조하였습니다. 연구자들이 조금 더 자유로운 연구를 할 수 있는 기회를 제공한다는 점에서 의미가 있을 것 같습니다.
3) 마지막으로 언급된 특징은, single agent만을 학습시킬 수 있었던 이전에 제안된 환경들과 달리, GRF는 multi-agent간의 협업, 경쟁을 시험할 수 있는 환경이라는 것이었습니다.
이러한 3가지 특징을 통해, GRF는 다음과 같은 장점을 제공한다고 저자들은 또한 주장하였습니다.
1) GRF는 이전에 제안된 환경들에 비하여 self-play, multi-agent leraning, model-based RL을 학습하고 검증하기에 이상적인 환경이라고 주장하였습니다.
2) 내부 소스 코드를 수정할 수 있는 자유로움과, 뒤에서 얘기할 다양한 수준의 예제 제공을 통해, 연구자들이 다양한 단계의 의사결정 (decision, strategy, tactics)를 학습할 수 있을것이라고 주장하였습니다.

이 장에서는, GRF의 환경을 이용하기 위해 알아야하는 정보를 간단히 말씀드리겠습니다. GRF는 기존의 축구 게임에서 지원하는 규칙들이 대부분 구현되어 있다고 합니다. 또한, 스탯이 다양한 선수들의 초기 포지션을 이용자가 자유롭게 설정할 수 있으며, 난이도를 설정할 수 있는 AI bot을 탑재하고 있다고 합니다.
이러한 GRF에서 제공하는 Observation과 Action 역시 정말 다양했습니다. 이 부분은 하나하나 설명하기 보다, 논문 혹은 공식 문서를 통해 참고해야 할 정도로 굉장히 많습니다. (115 차원의 vector를 통한 내부 게임 정보, 게임 화면 등의 observation, 이동, pass를 포함한 굉장히 다양한 action set)

또한, 환경을 이용하는 연구자들이 단계별 reward 검증 및 새로운 research idea test를 하기 위한 11개의 예제 scenario set을 저자들은 제공해 주고 있었습니다. 연구자들은 이러한 예제들을 이용하여 궁극적으로 레바뮌에 맞먹는?! 최강의 agent를 만들기 위하여, 단계적으로 goal을 잘 넣는 공격수와 goal을 잘 막는 골키퍼 등 단계적으로 agent를 학습시킬 수 있을 것입니다.


지금까지 설명드린 ALE 환경과 DeepLab, GRF이외에도 여러 유명한 환경들이 있습니다. 그 중, 대표적인 두 개의 환경에 대해서 간단히만 소개해 드리도록 하겠습니다.
첫 번째는, DeepMind에서 제공한 Control Suite라고하는 환경입니다. 이 환경은 2족 보행 등의 continuous control 문제를 해결하기 위해 DeepMind에서 제공하는 환경입니다. 그림에서도 볼 수 있듯 다양한 continuous control 예제들이 준비되어 있습니다.
두 번째는, GRF 이전에 Multi-agent 강화학습 문제를 풀기 위해 Geek-ai에서 제공한 MAgent라고 하는 환경입니다. 이 환경에서는, 2차원의 군집 점 객체들의 battle, move 등 다양한 시나리오를 학습 할 수 있도록 인터페이스를 제공합니다.
강화학습이 trial-and-error 방식을 통해 학습 되기 때문에, 바로 필드로 나가 학습하는 것은 거의 불가능하고, 그렇기에 이처럼 다양한 simulator 혹은 환경들의 가치가 높을 수 밖에 없다는 생각이 듭니다.
이번에도 긴 글을 읽어주신 점 감사드립니다.
전체 슬라이드와 논문 링크는 밑에 준비되어 있습니다.
The Arcade Learning Environment: An Evaluation Platform for General Agents
In this article we introduce the Arcade Learning Environment (ALE): both a challenge problem and a platform and methodology for evaluating the development of general, domain-independent AI technology. ALE provides an interface to hundreds of Atari 2600 gam
arxiv.org
DeepMind Lab
DeepMind Lab is a first-person 3D game platform designed for research and development of general artificial intelligence and machine learning systems. DeepMind Lab can be used to study how autonomous artificial agents may learn complex tasks in large, part
arxiv.org
Google Research Football: A Novel Reinforcement Learning Environment
Recent progress in the field of reinforcement learning has been accelerated by virtual learning environments such as video games, where novel algorithms and ideas can be quickly tested in a safe and reproducible manner. We introduce the Google Research Foo
arxiv.org