이 글은 현재 활동중인 팀블로그에 함께 작성 되었습니다.
https://ropiens.tistory.com/215
editor, Seungeon Baek(백승언)
Reinforcement learning Research Engineer
[Kor]
안녕하세요, 오랜만에 블로그를 쓰게 되네요! 이번 글은 논문 리뷰가 아닌, 강화학습 관련한 저의 첫 포스팅 글입니다.
이번에 작성하는 글에서 다루고자 하는 내용은 "강화학습은 어떤 문제를 풀 수 있는가?"입니다. 이와 관련하여, 비슷한 글이 있는지 여러 키워드로 검색을 해 보았는데 강화학습이 어떤 문제를 풀 수 있는지에 대한 내용보다는, 강화학습이 현재 적용되고 있는 분야와 관련된 블로그들이 대부분임을 알 수 있었습니다. (Application of RL, Usage of RL,... etc)
그렇기에, 부족하지만, 제가 한 번 강화학습이 어떤 문제를 풀 수 있는지에 대한 것을 주제로 글을 작성해보자 하는 생각이 들어, 해당 주제를 선정하였습니다. (요즘 핫한 ChatGPT도 슬쩍 끼워 넣어 보았습니다 :D)
그럼, 본격적인 포스팅 시작 하겠습니다!
[Eng]
Hello, it's been a while since I wrote a blog post! This post is not a review of a paper but rather my first post on the topic of reinforcement learning.
In this post, I want to cover the topic of "What problems can reinforcement learning solve?". In researching this topic, I searched for various keywords to see if there were any similar articles. Still, I found that most of the blogs related to reinforcement learning were focused on the current fields where it is being applied(Application of RL, Usage of RL,..., etc.) rather than what problems reinforcement learning can solve. (I also sneakily inserted ChatGPT, which is trendy these days :D)
Therefore, even though it may be lacking, I have decided to write a post on what RL can do.
So without further ado, let's get started with the post!

[Kor]
이번 포스팅 자료의 제목은 What can RL do?로 선정하였습니다. 최근 들어, 유명한 ChatGPT에도 강화학습(RLhf)이 적용 되며, 강화학습에 대한 관심이 늘었지만, 과연 "내 문제에도 강화학습을 적용할 수 있을까?"를 고민하고 계시는 분들께 도움이 될만한 자료라고 생각해주시면 될 것 같습니다.
[Eng]
The title of this post is "What can RL do?". Recently, reinforcement learning(RL) has been applied to famous models like ChatGPT, which has increased interest in RL. However, for those who are wondering, "Can RL be applied to my problem?" this post can be a helpful resource
[Kor]
발표 순서는 다음과 같습니다. 먼저 도입부에서 강화학습이 무엇인지에 대해 간단히 설명을 드리고, 강화학습이 집중해서 풀어온 문제들에 대해, 알고 있는 지식 하에서, 8가지 범주로 나누어 설명을 드리고자 합니다. 흐흐 이렇게나 많은 문제를 풀 수 있다니!
- Control problem
- Multi-armed bandit problem
- Combinatorial optimization
- Cooperative behavior learning
- Competitive behavior learning
- Mixed behavior learning
- Learning from human experts
- Learning from human feedback
[Eng]
The presentation order is as follows. First, in the introduction, I will briefly explain what RL is. Then, based on existing knowledge, I will explain the problems that reinforcement learning has been focused on solving, divided into eight categories. Wow, RL can solve so many problems!
- Control problem
- Multi-armed bandit problem
- Combinatorial optimization
- Cooperative behavior learning
- Competitive behavior learning
- Mixed behavior learning
- Learning from human experts
- Learning from human feedback

[Kor]
먼저, 도입부입니다.
[Eng]
First, let's begin with the introduction
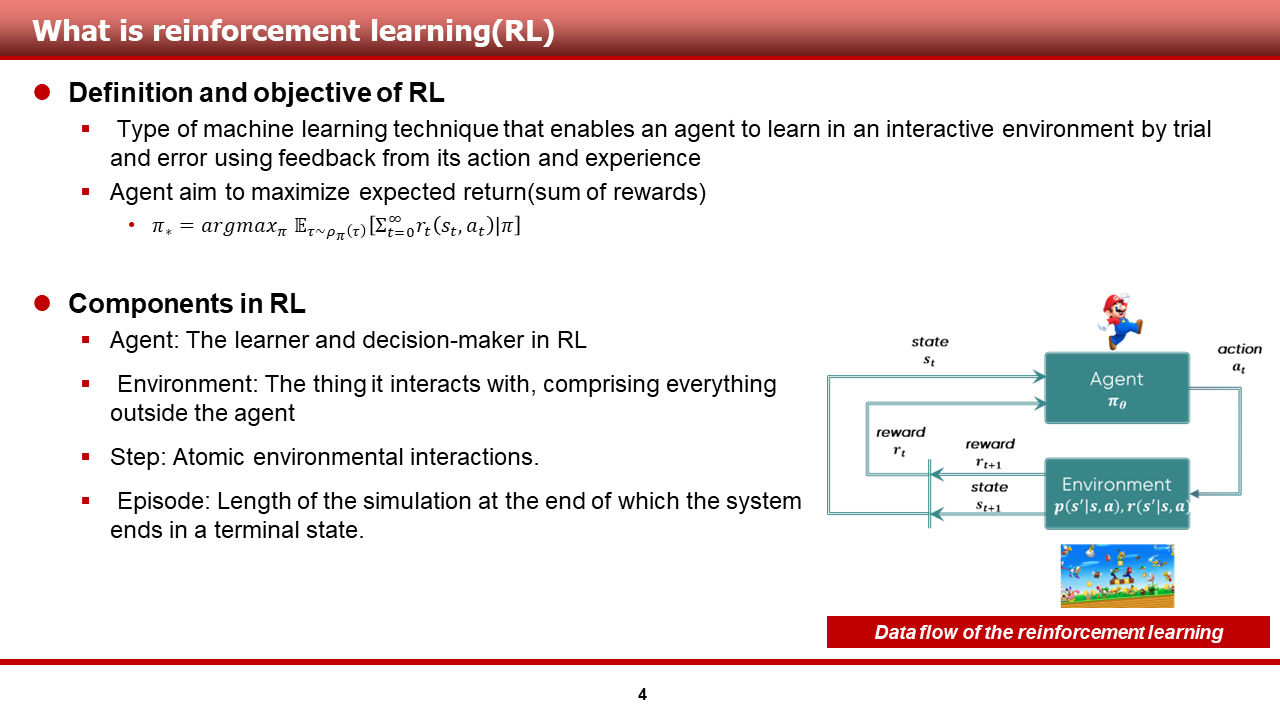
[Kor]
이 장과 다음 장에서는, 강화학습의 정의, 목적, 강화학습의 몇몇 중요 요소들에 대해서 말씀을 드리고자 합니다.
강화학습의 정의는 다음과 같습니다.
- "agent와 환경이 상호 작용을 하며, 이를 통해 얻은 행동에 대한 피드백과 경험들을 토대로 agent를 학습할 수 있게 하는 머신러닝 기법의 종류 중 하나".
또한, 강화학습의 목적은 다음과 같습니다.
- "에피소드의 끝까지 agent가 받는 보상의 총 합(sum of reward)를 최대화하는 것"
- 혹은 "최대화 할 수 있게끔 하는 정책(policy)을 학습하는 것"
강화학습의 중요 요소들은 다음과 같습니다. 이 장에서는, 공학적인 용어보다는 중요한 용어들을 위주로 준비해 두었습니다.
- Agent: 강화학습 내에서 학습을 수행하는 것 혹은 의사 결정자
- Environemnt: 에이전트를 제외한 모든 것들을 포함하는 것
- Step: 환경과 에이전트의 단위 상호작용
- Episode: 시스템이 끝나거나, 종료 상태에 도달 할 때까지의 스텝의 길이
[Eng]
In this slide and the next, I would like to discuss the definition, purpose, and some important components of RL.
The definition of RL is as follows:
- "Type of machine learning technique that enables an agent to learn in an interactive environment by trial and error using feedback from its action and experience"
In addition, the purpose of RL is as follows:
- "To maximise the total sum of rewards(return) received by the environment until the end of the episode"
- Or "To learn a ppolicy that can maximise the reward"
The important elements of RL are as follows. In this chapter, I have prepared important terms rather than mathematical terms.
- Agent: What performs learning and decision-making in RL
- Environment: Everything outside the agent
- Step: Unit interaction between the agent and the environment
- Episode: The length of steps until the system ends or reaches a terminal condition(state)
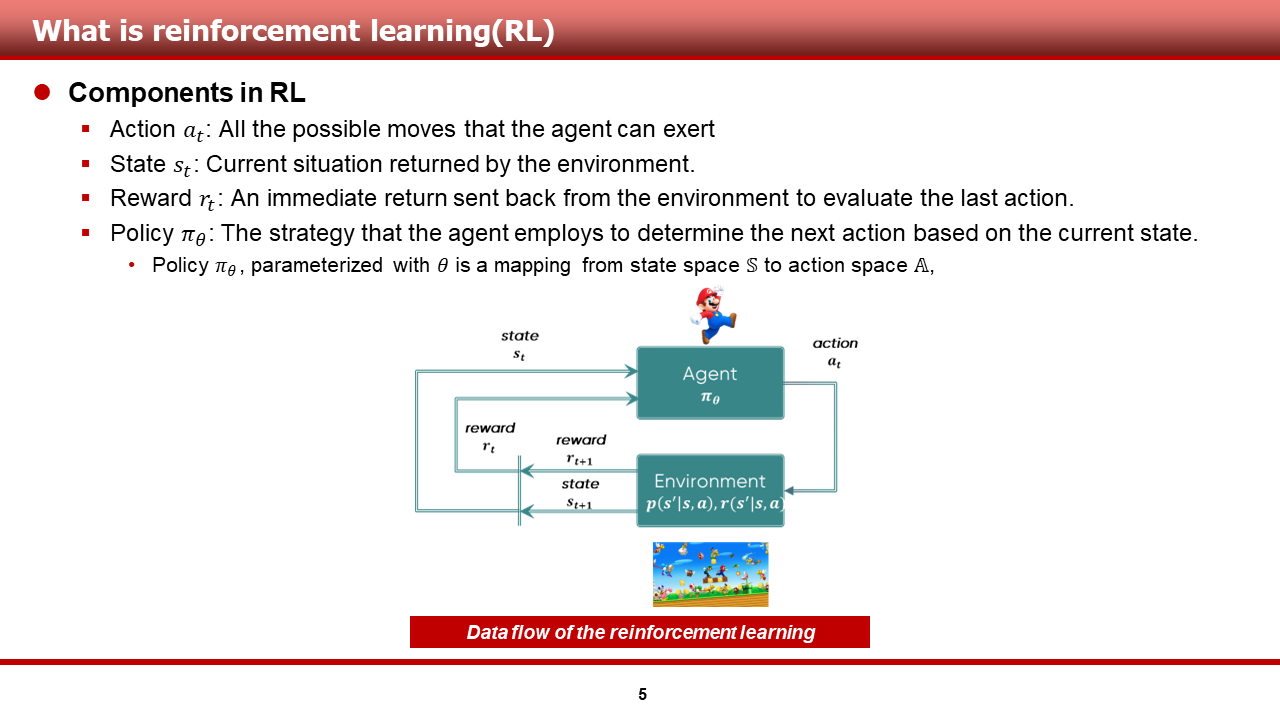
[Kor]
강화학습의 중요 요소들은 다음과 같습니다.
- Action: Agent가 실행 가능한 모든 가능한 움직임들
- State: 환경으로 부터 받은 현재 상황
- Reward: 마지막 행동에 대한 평가로써, 환경으로 부터 받은
순시 반환 값피드백 - Policy: 현재 상황을 기반으로, 다음 액션을 정의함에 있어서, 에이전트가 활용하는 전략
- 정책 policy는 state space S로부터 action space A로의 사상이며(정의역이 상태 공간, 치역이 행동 공간인 함수!) 보통 theta라고 하는 파라미터로 모수화 되어 있음.
이러한 사전 지식을 활용하여, 장애물을 모두 피해서 도착 지점에 잘 도착하는 슈퍼 마리오(agent)를 학습시키는 예제에 대해서 설명해 보겠습니다.
슈퍼 마리오(RL agent)는 방향키와 대쉬, 점프 키(action) 등을 활용하여, 도착 지점(terminal state)에 도착하기 위해 스테이지 내에서(environment) 이런저런 시도를 해보며(trial and error), 환경으로 부터 점수(feedback)를 받고(굼바를 못 피하면 -10, 거북이를 못 피하면 -10, 금화를 먹으면 +1, 도착점에 도착하면 + 200 등), 이를 통해 특정 상황(state)에서, 어떤 방향키(action) 및 특수 키를 눌러야 하는지에 대한 승리 전략(policy)을 수립하게 된다!
어지럽다고요? 죄송합니다. 필력이 좋지가 않네요ㅎ
[Eng]
The important elements of reinforcement learning are as follows.
- Action: All the possible moves that the agent can exert
- State: Current situation returned by the environment
- Reward: An immediate return sent back from the environment to evaluate the last action
- Policy: The strategy that the agent employs to determine the next action based on the current state
- Policy, parameterized with \theta is a mappping from state space S to action space A
Using this prior knowledge, let me explain an example of training Super Mario(agent) to arrive at the destination point by avoiding all obstacles.
The Super Mario(reinforcement learning agent) uses directional keys, dash, jump key(action), etc., to try various approaches(trial and error) to reach the destination point(terminal state) in certain stage(environment). The Super Mario receives score(feedback) from the environment(such as -10 if it fails to dodge a Goomba, -10 for failing to dodge a Koopa Troopa, +1 for collecting a coin, and +200 for arriving at the destination point). Through this, the agent establishes a 쟈ㅜwinning strategy(policy) for which direction key(action) and special key to press in a specific situation(state).
Confusing? I'm sorry. My writing skills are not that great.

[Kor]
이 장부터는 본격적으로 강화학습이 집중해서 풀어온 문제들에 대해, 각각의 카테고리 별로 간단한 설명과, 예제 문제들을 소개해 드리도록 하겠습니다.
[Eng]
Starting from this slide, I will focus on the problems RL has been tackling and introduce summaries and examples for each category.

[Kor]
먼저, 강화학습 agent는 control problem을 해결할 수 있습니다. Control problem이란, 특정 환경 내에서, 강화학습 agent가 object를 제어하는 문제라고 말씀드릴 수 있을 것 같습니다.
이때, 강화학습 agent는 해당 문제를 다양한 레벨로 다룰 수 있습니다. 인지 - 의사결정 - 제어의 모든 과정을 end-to-end로 다룰 수가 있고, 이러한 연구는 한정된 환경에서 학습을 수행하는 로봇 연구에서 많이 채택됩니다. 또한, 의사결정 - 제어의 부분만 강화학습 agent가 다룰 수 있습니다. 이는 인지 기술이 많이 발달한 자율주행자동차 연구에서 주로 행해지는 것 같습니다. 뿐만 아니라, 강화학습은 시스템의 일부를 제어만 할 수도 있습니다.
이러한 강화학습을 이용해 control problem을 해결 해온 연구의 예시로는, 로봇 팔 도메인에서 블록 쌓기 등의 복잡한 task를 end-to-end로 학습하는 사례들이 있으며, 또한, 자율주행 자동차 도메인에서 decision and control problem을 학습하는 사례 등이 있을 것 같습니다.
[Eng]
First, an RL agent can solve control problems. Control problems can be described as problems where the RL agent controls an object in a particular environment.
The RL agent can handle the problem at various levels in this case. It can handle the entire perception, decision-making, and control process end-to-end. This type of research is often adopted in a robot domain where learning is performed in a limited environment. In addition, the agent can only handle decision-making and control as part of the process. This is mainly done in autonomous driving research, where perception technology has advanced. Furthermore, RL can also control only part of the system.
Examples of research that have solved control problems using RL include learning complex tasks such as block stacking in the robot arm domain through end-to-end learning and learning decision and control problems in the autonomous driving domain.
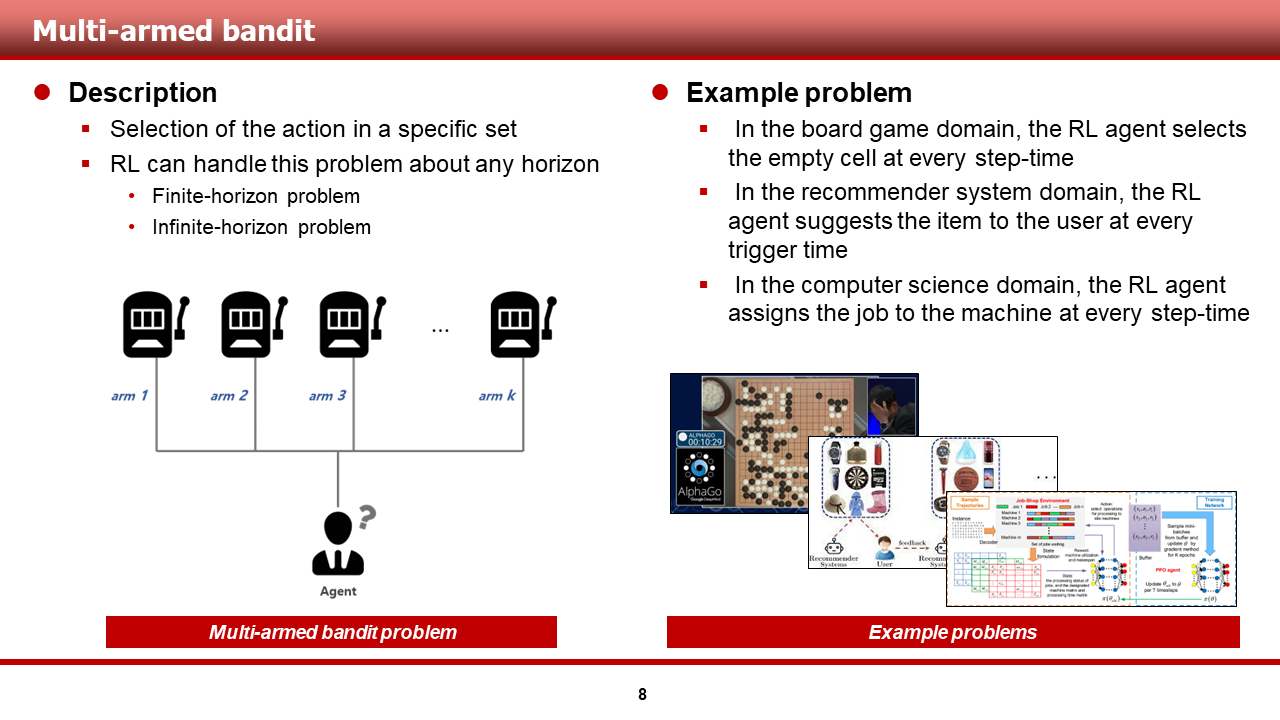
[Kor]
두 번째로, 강화학습 agent는 multi-armed bandit problem을 해결할 수 있습니다. Multi-armed bandit problem이란 특정 집합에서 행동을 선택하는 문제라고 말씀드릴 수 있을 것 같습니다.
이때, 강화학습 agent는 해당 문제를 다양한 horizon으로 다룰 수 있습니다. 유한한 길이의 문제 뿐만 아니라, 무한한 길이의 문제도 잘 다룰 수 있다는 것이 근본 책, 논문 등에서 수학적으로 다루어져 왔습니다.
이러한 강화학습을 이용해 multi-armed bandit problem을 해결해온 연구의 예시로는, 보드 게임 도메인에서의 연구가 있을 것 같습니다. 바둑 같은 경우, 매 스텝 빈칸 중 승률이 높아 보이는 칸을 선택하는 문제로 해석할 수 있지요! 또한, 추천 시스템 도메인 역시 매 트리거 타임마다 user에게 item set 중 아이템을 선택하여 유저에게 추천해 주기 때문에, 많은 연구가 수행되고 있는 것으로 알고 있습니다. 또한, CS 도메인에서는 매 스텝 머신에게 job을 할당하는 문제인 job-shop scheduling 문제에서 강화학습이 이러한 관점으로 적용이 되고 있다고 알고 있습니다.
[Eng]
Secondly, an RL agent can solve the multi-armed bandit problem, which can be described as a problem of selecting actions from a specific set.
In this case, the RL agent can handle this problem from various horizons. It has been mathematically treated in the literature as well as in papers, not only for finite-length problems.
Examples of research that have solved the multi-armed bandit problem using RL include studies in board game domains. For example, in the game of Go, the problem can be interpreted as selecting a blank space with a high winning probability at each step. In addition, in the domain of recommendation systems, many studies have been conducted as the system recommends an item to a user by selecting an item from an item set at each trigger time. Also, in the computer science domain, RL is being applied from this perspective in job-shop scheduling problems where a machine is assigned a job at each step.

[Kor]
다음으로, 강화학습 agent는 combinatorial optimization problem을 해결 할 수 있습니다. Combinatorial optimization problem이란 주어진 특정 집합 내에서 최적의 결정들(결정들의 조합)을 내리는 문제라고 말씀드릴 수 있을 것 같습니다.
이때, 강화학습 agent는 이를 1 step MDP로 간주 하여, 해당의 조합 최적화 문제를 해결해 낼 수 있다는 것이 최근 들어 많은 연구 사례들이 보여주고 있습니다.
이러한 강화학습을 이용해 combinatorial optimization problem을 해결 해 온 연구의 예시로는, 웨이퍼 상에 칩들을 배치하는, chip placement도메인에서의 연구가 있을 것 같습니다. 또한, routing problem 분야에서도, 단일 차량 혹은 다중 차량의 운행 순서를 정해주는 등 강화학습을 이용하여 여러 연구들이 진행되고 있는 것으로 알고 있습니다.
뿐만 아니라, 강화학습은 수학 문제를 해결할 수 있는데, 지도학습에서 특정 task를 학습하기 위해 어떤 loss 식이 좋은지를 graph 혹은 symbolic으로 표현된 term들의 최적의 조합을 찾는 방식으로 해당 문제를 해결하는 것이 가능합니다.
[Eng]
Next, an RL agent can solve combinatorial optimization problems. Combinatorial optimization problems refer to problems of making optimal decisions(combination of decision) witn a certain set.
In this case, the reinforcement learning agent can consider it as a 1-step MDP and solve the combinatorial optimization problem, as many recent reserach cases have shown.
Examples of research that has used reinforcement learning to solve combinatorial optimization problems include chip placement domains, where chips are placed on a wafer, and the routing problem field, where reinforcement learning is used to determine the operating order of single or multiple vehicles.
In addition, reinforcement learning can solve mathematical problems. In supervised learning, it is possible to solve problmes by finding the optimal combination of graph or symbolically expressed terms that are good for a given loss function used to learn a specific task.

[Kor]
또한, 강화학습 agent는 cooperative behavior learning problem을 해결할 수 있습니다. 협력적인 행위를 학습한다는 것은, 주어진 특정 환경 내에서 여러 객체들이 하나의 목표를 달성하기 위한 행위들을 학습한다는 것으로 말씀드릴 수 있을 것 같습니다.
이때, 강화학습은 해당 문제를 individual reward만을 줘서 해결 할지, team reward를 주어 credit assignment까지 풀어낼지를 세팅하여 해결할 수 있습니다.
강화학습을 이용해 cooperative behavior를 학습해온 연구의 예시로는, 통신 도메인에서 기지국이 모든 사용자들을 고려해 편익이 최대로 하는 방향으로 resource를 분배하는 등의 연구가 있을 것 같습니다.
또한, 게임 분야에서도, 이러한 협력적인 행위를 학습하기 위한 연구들이 많이 수행되고 있으며, 대표적으로 SMAC이라고 하는, 3s vs 5z 등 다중 유닛이 협력하여 상대방을 쓰러뜨리는 행위를 학습하는 환경에서 여러 연구들이 수행되고 있는 것으로 알고 있습니다.
[Eng]
Moreover, an RL agent can solve cooperative behavior learning problems. Learning cooperative behavior menas learning actions by multiple objects within a given environment to archive a team goal.
In this case, RL can solve the problem by setting wheter to give individual rewards or team rewards, and solving the credit assignment when giving team rewards.
Examples of research that has used RL to learn cooperative behavior include studies in the communication domain, such as the dstribution of resource by base stations considering all users for maximum benefit.
In addition, in the game domain, many studies are being conducted to learn such cooperative behavior, and there are several studies carried out in environments where multiple units cooperate to take doooown opponents, such as 3s vs 5z, known as SMAC envrionment.

[Kor]
더욱이, 강화학습 agent는 competitive behavior learning problem을 해결 할 수 있습니다. 경쟁적인 행위를 학습한다는 것은, 주어진 특정 환경 내에서 여러 객체들이 zero-sum game을 수행하고, 각자가 상대에 대응해 이기기 위한 전략을 학습한다는 것으로 말씀드릴 수 있을 것 같습니다.
강화학습을 이용해 competitive behavior를 학습해온 연구의 예시로는, 가장 유명한 AlphaGo, AlphaStar 등이 있을 것 같습니다. 워낙 유명한 연구들이지요.
[Eng]
In addition, an RL agent can solve competitive behavior learning problems. Learning competitive behavior menas that multiple objects perform a zero-sum game in a given environment and learn strategies to truimph against each other.
Examples of studies that have used RL to learn competitive behavior include the famous AlphaGo and AlphaStar. Theses studies are very well known!

[Kor]
이 뿐만 아니라, 강화학습 agent는 cooperative behavior와 competitive behavior가 혼합된, mixed behavior를 학습할 수 있습니다. 예시로 슬라이드에 첨부한 Predetor-Prey game 환경처럼, 동일 그룹 내에서는 협력적인 행위를, 타 그룹과는 경쟁적인 행위를 동시에 학습할 수 있는 것이죠.
이러한 강화학습의 능력에 힘입어, game domain에서는 11 vs 11 축구를 관제하는 big brother와 같은 centralized agent를 학습할 수 있었고(Google Research Football Environment), 자율주행 자동차 도메인 내에서는 Mixed autonomy 하에서 일반 차량들과 조화를 이루는 자율주행 자동차의 제어 방법이 연구되고 있습니다.
[Eng]
Furthermore, an RL agent can learn mixed behaviors, which combine cooperative and competitive behaviors. For example, in an environment such as Predetor-Prey game figured to the slides, agents can learn both cooperative behavior within the same group and competitive behavior with other groups.
Thanks to this ability of RL, centralized agents like the big brother controlling 11 vs 11 soccer games in the game domain(Google Research Football Environment) have been developed, and in the autonomous vehicle domain, research is being conducted on controlling autonomous vehicles that harmonize with human vehicles under mixed autonomy.

[Kor]
그리고, 강화학습 agent는 learning from human experts(demonstration)컨셉으로 학습할 수 있습니다. 해당 방법론을 이용하는 강화학습 기법들은 인간(전문가)의 시연데이터를 통해 학습을 수행하기 때문에, 밑바닥부터 학습하는 기존의 강화학습들에 비하여 복잡한 task를 상대적으로 쉽게 학습해 낼 수 있다고 말씀드릴 수 있을 것 같습니다.
이러한 방식을 통해 학습한 강화학습 연구의 예시로는, 자율주행 자동차 도메인 내에서 복잡한 시나리오(회전 교차로, 신호 교차로, 도심부 주행 등) 에서의 계획 및 제어를 수행하는 연구가 있을 것 같습니다. 또한, 금융 분야에서 복잡한 시장 상황을 고려하여 주식을 사고파는 트레이딩 봇 같은 경우도 이러한 RLfD(Reinforcement Learning from Demonstration) 컨셉의 연구들이 있는 것으로 알고 있습니다.
뿐만 아니라, 최근 DeepMind의 GATO라고 하는 agent는 실제 사람처럼 "여러 개"의 게임을 사람 이상의 실력으로 클리어하는 괴물과 같은 모습도 보여주었습니다. 해당 agent는 human experts의 demonstration을 통해 학습이 이루어졌답니다.
[Eng]
And then, an RL agent can learn from human experts(demonstration). RL techniques that use this concpet can leaern complex tasks relatively easily compared to traditional RL methods, as they leveraging the knowledge through human demonstration data rather than starting from scratch.
Examples of RL research learned through this approach, there are studies that perform planning and control in complex scenarios(such as turning intersections, signal intersections, and urban driving) in the autonomous vehicle domain. Also, in the finantial sector, there are studies on trading bots that buy and sell stocks considering complex market situations based on the RLfD(Reinforcement Learning from Demonstration) concept.
Moreover, DeepMind's recent agent called GATO showed a monstrous capability to clear "multiple games" with human-level proficiency. The agent learned through demonstration from human experts.

[Kor]
마지막으로, 강화학습 agent는 learning from human feedback(preference)컨셉으로 학습할 수 있습니다. 해당 방법론을 이용하는 강화학습 기법들은 인간의 직접적인 feedback을 받아 학습을 수행하기 때문에, 자연스러운 action을 생성해 낼 수 있다는 것이 장점으로 생각됩니다.
이를 실현하기 위해, 기존의 강화학습과는 조금 다르게, 환경은 reward를 제공하지 않게 됩니다. 대신에, 사람이 observation을 보고 feedback을 주면, 특별한 모델인 reward predictor가 사람의 feedback을 통해 reward 함수를 모델링, 해당 reward 모델과 함께 강화학습 agent가 학습되는 방식인 것 같습니다.
이러한 방식을 통해 학습한 강화학습 연구의 예시로는, 유명한 Open AI의 로봇 "손" 큐브 풀기 연구(DAgger)가 있을 것 같습니다. 사실은 reward predictor를 이용해 학습이 되지는 않았지만, 계속하여 사람이 더 좋은 행위를 개입해서 알려주는 DAgger의 방식이 RLhf(RL frorm human preference)와 철학적으로는 비슷하다고 생각하여 넣어 보았습니다.
더욱이, 해당 방식은 LLM(Large Language Model)과 결합하여, 최근 돌풍을 일으키고 있는 ChatGPT!!를 가능하게 한 기술이기도 합니다. RLhf 덕분에 ChatGPT는 조금 더 친절하고, 조금 더 자연스럽고, 또한 혐오 발언 등을 자제할 수 있었다고 합니다.
[Eng]
Finally, an RL agent can also learn from human feedback(preference). The RL techniques that use human feedback can generate natural actions as they receive direct feedback from humans.
To achieve this, the environment does not provide rewards as in traditional RL. Instead, humans give feedback based on observations, and a special model called the reward predictor models the reward function based on the human feedback. The RL agent is trained with this reward model.
An example of RL research using this approach is the famous OpenAI's robot hand solving a Rubik's cube using the DAgger algorithm. Although not trained using the reward predictor, the DAgger approach continuously incorporates better behaviores informed by human feedback, which is similaar philosophically to RLhf(Reinforcement Learning from human preference)
Moreover, this approach can be combined with LLM(Large Language Model) technology, which has recently gained popularity in the form of ChatGPT. Thanks to RLhf, ChatGPT can be more friendly, natural, and also avoid hate speech.

[Kor]
정말로 오랜만에 블로그 글을 쓰게 되었는데, 여기까지 읽어 주신 모든 분들께, 짧지 않은 글을 읽어 주셔서 감사하다는 말씀을 드립니다. 궁금하신 점들은 댓글을 통해 질문을 주시면 가끔씩이라도 들러 답변을 드릴 수 있도록 하겠습니다.
[Eng]
This is my first time writing a blog post in Eng, and I would like to thank those who have read this lengthy post. If you have any question, please feel free to leave a comment and I will try to drop by and provide answers whenever possible.