가짜연구소 5기 멀티태스크메타러닝-초읽기 아카데믹 러너 활동을 통해 위의 논문을 읽게 되었습니다.
노션을 복붙 해오니 영 마음에 들진 않지만..! 제가 주로 다루는 분야가 아니기에, 가볍게 정리하는 느낌으로 가져가볼까 합니다.
Universal Language Model Fine-tuning for Text Classification
Abstract
- Inductive transfer learning은 CV에서 많은 impact를 주어 왔으나, NLP에서 많이 연구가 되지 않았음을 지적. 또한, task-specific한 modification이나 training from scratch가 필요했음을 언급.
- 이에 저자들은 any task in NLP에 적용이 가능한 효율적인 transfer learning 기법인 Universal Language Model Fine-Tuning(ULMFiT)를 제안함. 그리고, language model을 fine tuning 하기 위한 핵심 기법을 소개함.
- 저자들의 기법은 6개의 text classification task들에서 SOTA를 상당히 뛰어넘는 성능을 보여주었다고 함.
- 뿐만 아니라, 단 100개의 labeled example 만으로, 백배 많은 data를 training from scratch한 것보다 좋은 성능을 보여주었다고 함.
Introduction
Inductive transfer learning은 CV에서 많은 impact를 주어 왔다고 함. OD, classification, segmentation등 다양한 도메인에서, trained from scratch는 매우 드물다고 함. ImageNet, MS-COCO등으로 pre-train된 모델을 보통 사용하기에.
NLP의 범주 중 하나인 text classification task는 spam, fraud and bot detection, emergency responce and commercial document classification 등등을 다룬다고 하는 것 같음.
DL model들이 많은 NLP task들에서 SOTA를 성취해 왔음에도 불구, 이러한 모델들은 많은 데이터셋과 함께, scratch로부터 학습을 해왔다고 함.
NLP 도메인에서의 연구는 주로 transductive transfer에 초점을 두었다고 함. Inductive transfer 영역에서는 fine-tuning pre-trained word embedding 등의 model의 first layer만을 타겟으로하는 간단한 transfer technique많이 연구되어 왔다고 하는 것 같음.
최근의 different layer의 input으로 다른 task로부터 유도된 embedding을 concatenate 하는 접근들은 아직도 main task model은 scratch부터 학습을 해야 하고, pretrained embedding들은 그것의 유용성이 제한되는, fixed parameter로 다뤄야 했다고 함.
pretraining의 이점이 빛을 발하기 위해, 연구자들은 random 초기화보다 더욱 좋게 할 수 있어야만 한다?? 고함.
그러나, inductive transfer via fine-tuning은 NLP에서 성공적이지 못해 왔다고 함. 이전 연구 언급
LM(Language Model)들은 small dataset에 오버피팅 되기도 하며, classifier와 함께 fine-tune 될 경우, catastrophic forgetting을 겪기도 한다고 함.
- Compred to CV, NLP model들은 조금 더 shallow 하고, 그래서 조금은 다른 fine-tuning 기법들을 요구한다고 함
- 저자들은 이러한 이슈들을 해결할 수 있고, 강건한 inductive transfer learning을 할 수 있는, ULMFiT라고 하는 새로운 기법을 제안한다고 함.
- IMDB에서, 100개의 labeled example들과 함께, ULMFiT는 10배 이상의 training from scratch와 맞먹는 성능을 보여주었다고 하며, unlabeled data로 학습을 할 시에는 100배 이상의 성능을 보여주었다고 함.
- Contribution
- NLP의 any task로 CV 처럼 transfer learning 할 때 사용할 수 있는 ULMFiT를 제안
- previous 지식을 유지하면서 새로운 기법을 배우고, fine tuning 동안 catastrophic 망각을 회피하기 위해, discriminative fine-tuning, slanted triangular learning rates, and gradual unfreezing등을 제안.
- 6개의 text classification 과 관련된 majority dataset들에서 SOTA를 상당히 뛰어넘는 성능을 보여주었다고 함.
- 제안된 기법이 굉장히 sample efficient transfer learning이라는 것을 보여주고, 광범위한 ablation study를 수행했다고 함
- 저자들은 pre-trained model들과 코드를 공개함 멋지다…
Related work
- Multi-task learning
해당 접근법은 Rei, Liu등이 제안했으며, language modeling objective를 main task에 추가하는 방식으로 이루어졌었다고 함.
MT learning은 매번 scratch로부터 훈련이 되어야 하는 task들을 필요로 한다고 하며, task-specific objective function의 weight들을 신중히 정해야 하는 비효율 적인 과정이 종종 필요하다고 함
- Fine-tuning
Fine-tuning은 similar task사이에 transfer를 성공적으로 하기 위해 사용되어 왔다고 함. 예를 들면 Min et al의 QA, severyn등의 distantly supervised sentimental analysis or MT domain 등을 언급.
또한, Dai and Le도 LM을 fine tune 했다고 함. 그러나, 굉장히 많은 데이터셋을 필요로 했다고 함. 대조적으로, ULMFiT는 general-domain pretraining을 leverage하며, small dataset만으로 SOTA를 달성했다고 어필함
Methodology
저자들은 NLP를 위한 inductive transfer learning에 흥미가 있다고 합니다. static source task $T_S$와 target task $T_T$가 주어졌다고 할 때, 저자들은 $T_T$의 성능을 개선할 것이라고 합니당.
LM은 ideal source task로 보고 있다고 하며, CV에서의 ImageNet에 대항할 수 있는 task로 간주한다고 하는 것 같습니다.
이는 long-term dependencies, hierarchical relations, and sentiment 등의 언어 관련된 downstream task의 많은 측면을 capture할 수 있다고 말하는 것 같습니다.
MT혹은 entailment와는 대조적으로, 제안하는 기법은 거의 무제한의 quantities for most domains and languages에를 제공한다고 함. 추가적으로, pretrained LM은 target task의 성능이 상당히 개선되는, 특이점에 쉽게 다다른다고 설명함.
더욱이, LM은 Machine translation, dialogue modeling 같은 기존의 task들의 key component라고도 하는군용
공식적으로, LM은 많은 다른 NLP task들에 유용한, 가설 공간 H를 유도해낼 수 있다고 서술한 다른 논문들을 인용.
저자들은 large general-domain corpus에서 pretrain하고, 새로운 기법을 사용해 target task에 fine-tune하는 ULMFiT를 제안했다고 함
이 기법은....!!
1) 다양한 document size, number and label type을 다루는 task들에 대해 동작하며
2) single architecture and training process를 가졌으며,
3) custum feature engineering or processing을 필요로 하지 않으며,
4) additional in-domain documents or label을 필요로 하지 않아, universal이라는 이름을 사용했다고 합니다.
저자들은 또한, 백본 모델로 SOTA language model인 AWD-LSTM을 사용했다고 합니다. (a regular LSTM(no attention, short-cut connections) with various tuned dropout hyperparams)
CV와 유사하게, 저자들은 미래에 NLP downstream task performance가 high-performance LM을 사용해서 향상되기를 기대한다고 합니다. 응?

ULMFiT는 1) General-domain LM pretraining 2) target task LM fine-tuning 3) target task classifier fine-tuning의 단계로 구성되어 있다고 합니다.
General-domain LM pretraining
ImageNet-like corpus for language는 거대해야 하며, language의 general property들을 capture해야 한다고 합니다.
그래서, 저자들은 28595 preprocessed wikipedia article들과 103 million words로 구성된, Wikitext-103에서 LM을 pretrain시켰다고 합니다.
pretraining은 small dataset을 가지는 task들에게 있어서 굉장한 이점이 있으며, 심지어 100개의 example만으로도 일반화를 할 수 있게 해 준다고 합니다. 하지만 비용이 매우 비싸기 때문에, 딱 한 번만 수행되면 좋다고 합니다.
Target task LM fine-tuning
pre training에 쓰인 general-domain data가 아무리 diverse하더라도, target task의 data는 다른 분포로부터 올 가능성이 있다고 서술. 그래서, 저자들은 target task의 data에 LM을 fine-tune했다고 합니다.
pretrained general-domain LM이 주어지면, 이 단계에서는 target data의 특이점에만 빠르게 적응하면 되므로, 수렴이 빠르다고 합니다. 그리고 이 과정은 small dataset에 robust한 train을 할 수 있도록 해준다고 합니다.
이때, 저자들은 뒤이어 설명할 discriminative fine-tuning and slanted triangular learning rates for fine-tuning the LM을 제안했다고 합니다.
1. Discriminative fine-tuning
different layer들이 다른 타입의 정보를 capture 함에 따라, 그것들은 different extents에 fine-tune되어야 한다고 서술. 그래서, 저자들은 discriminative fine-tuning이라고 하는 새로운 기법을 제안했다고 합니다.
모델의 모든 layer들에 대해 같은 learning rate를 사용하는 대신에, discriminative fine-tuning은 각 레이어가 다른 learning rate들로 tuning되게끔 한다고 합니다.
SGD update에 따라 $\theta$를 업데이트한다고 할 때, 특정 time t에서
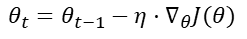
가 되는데, 이때 discriminative fine-tuning에서는 $\theta$를 $\{\theta^1, ... , \theta^L\}$ 요롷게 나누다고 합니당.
마찬가지로, learning rate eta역시 $\{\eta^1 , ... , \eta^L\}$ 요롷게 나눠진다구 하네용. 또한, 경험적으로 다음과 같이 설정했더니 잘 동작했다고 합니다.

2. Slanted triangular learning rates
제안하는 model의 parameter들이 task-specific feature에 adapting하게 하기 위해, 저자들은 model이 훈련 초기에 적절한 영역으로 빠르게 수렴한 다음, refine할 수 있도록 했다고 합니다.
same learning rate를 사용하거나, annealed learning rate를 훈련하는 동안 사용하는 것은 이를 위한 best way가 아니었다고 합니다.
⇒ 대신에, 저자들은 STLR이라고 하는, 선형적으로 증가하다가 선형적으로 감소하는, 다음과 같은 schedule을 가진 STLR을 제안했다고 합니다.

이때, T는 num of training iteration이며, cut_frac은 삼각형의 꼭짓점 위치인 것 같습니다. p는 얼마나 증가시키고 감소시킬 것인지에 대한 친구이며, ~~ 이때 저자들은 cut_frac을 0.1로, ratio를 32로, n_max를 0.01로 정했다고 합니다.
SLTR은 triangular learning rates(Smith, 2017)을 short increase and a long decay period로 수정한 버전이며, 저자들이 좋은 성능을 얻기 위한 key였다고 합니다. CV에서도 Loschilov and Hutter 2017의 논문에서 유사한 스케쥴링을 했다고 합니다. (aggressive cosine annealing)
3. Target task classifier fine-tuning
또한, classifier를 fine-tuning 하기 위하여, 저자들은 pretrained LM에 두 개의 additional linear block들을 추가하였다고 함.
다음의 CV classifier의 standard practice에서는 각 block이 batch norm과 dropout with ReLU activations for the intermediate layer를 사용했고, last layerdml 각 출력 확률에 대해서는 softmax activation을 사용했다고 하네용.
이러한 task-specific classfier layer들의 parameter들은 scratch로부터 학습이 된 유일한 친구라고 하며, 첫 번째 linear layer는 last hidden layer state들을 pool해서 사용했다고 합니다.
3-1. Concat pooling
text classification task의 signal은 종종 few work들을 포함하고 있다고 하며, 이 친구들은 document 어디에서나 있다고 함. 입력 문서는 hundreds of words들로 이루어져 있으며, 만약 저자들이 last hidden state of the model만을 고려한다면, 정보는 get lost 될 수 도 있다고함.
이러한 이유로, 저자들은 document의 last time step $h_T$에서의 hidden state를 concat했다고 합니다.

3-2. Gradual unfreezing
Fine-tuning the target classifier는 transfer learning 기법에서 가장 중요한 부분이라고 합니다. 너무 공격적인 fine tuning은 catastrophic forgetting을 야기할 수 있고, LM이 capture한 정보의 이점을 잃게끔 할 수도 있다고 합니다.
그렇다고, 너무 신중한 fine-tuning은 slow convergence를 야기할 수 있다고 합니다. 게다가, discriminative fine-tuning and triangular learning rates를 이용하기 때문에, 저자들은 gradual unfreezing이라는 것을 제안했다고 합니다.
Gradual unfreezing ⇒ 모든 layer를 한 번에 fine tuning하는 것이 아니라, 점진적으로 model을 unfreeze하는 방식. 최소 정보를 가지는 last layer를 시작으로 한 layer씩 unfreeze! 한 epoch당 하나의 layer를 unfreeze하는 식으로 한다구 하네용. 이는 chain-thaw 라는 Felbo et al 2017과 유사하다고 합니다.
3-3. BPTT for Text Classification (BPT3C)
LM은 BPTT를 통해 학습이 된다고 합니다. 그런데 large document에서의 classifier fine-tuning을 가능하게 하기 위해, 저자들은 BPT3C를 제안했다고 합니다.
저자들은 document를 각 fixed length batches of size b로 분할하고, model의 hidden states를 previous batch의 final state로 초기화하는 방식을 사용했다고 하네요. mean, max pooling도 그대로 keep track했다고 합니다.
3-4. Bidirectional LM
기존의 연구와 유사하게, 저자들은 해당 LM을 unidirectional 으로 제한하지 않고, forward and backward LM 모두를 pretrain 했다고 합니다.
Experiments
저자들의 접근은 sequence labeling task들에 적용이 가능하지만, 저자들은 실제 세상의 적용을 위해 중요한 태스크인 text classification task에만 신경을 조금 써봤다고 합니다.
4.1 Experimental setup
Datasets and tasks ⇒ 저자들은 많이 연구되어온 6개의 dataset들을 이용했다고 함. 이는 SOTA text classification and transfer learning 기법들인 Johnson and Zang 2017, McCann et al 2017에서 사용했다고 하는 것 같음.
task는 sentimental analysis, question classification, topic classification이라구 하네용
4.1.1 sentimental analysis
IMDB dataset의 binary movie review, binary and five-class version of the Yelp review dataset
4.1.2 Question classification
six-class version of the small TREC dataset
4.1.3 Topic classification
large-scale AG news and DBpedia ontology datasets
Pre processing은 기존 Johnson and Zang, McCann et al과 동일하게 사용했다고 하며, HyperParam은 Merity et al의 AWD-LSTM 모델을 사용했다고 하는 것 같습니다. 특이한 점은 Adam에서의 beta 1 을 0.9 ⇒ 0.7을 썼다는 것 정도가 있을 것 같네용.
⇒ 모든 dataset에 대해 hyper param은 고정했다고 합니다.
Baseline으로는 IMDb, TREC-6에서는 CoVe(McCann et al)를 선정하였고, AG, Yelp, DBpedia에서는 Johnson and Zang의 기법을 선정해서 비교를 수행했다고 합니다.
4.2 Results
error rates를 metric으로 하여 비교한 결과, 모든 데이터셋에서 꽤나 좋은 성능을 얻어냄. IMDb에서는 43.9% 정도로 에러율을 개선하는 정도.
Analysis and Ablation stydy
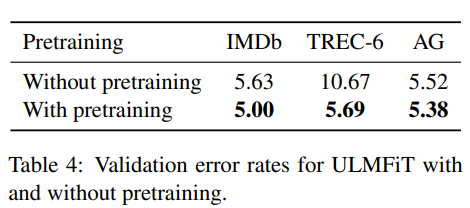
Impact of pretraining

pretraining을 하면 성능이 훨씬 좋다!
Impact of LM quality

LM으로 vanilla LM 말고, AWD-LSTM LM 사용한 것은 유효했다!
Impact of LM fine-tuning

Full 이라고 하는 fine-tuning 이전의 성능과 이후 성능 차이도 물론 차이가 나지만, discriminative learning rates, STLR 모두 유효했음을 보여줌
Impact of classifier fine-tuning
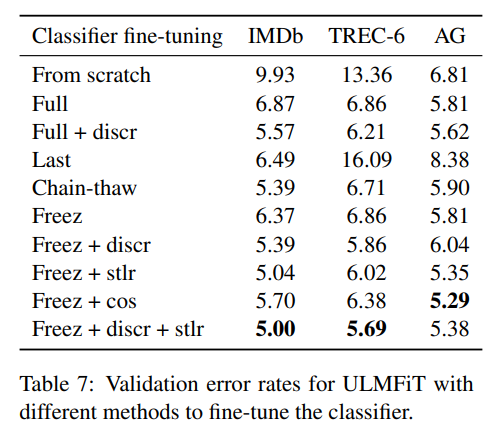
from scratch, fine-tuning full model(’full), fint-tuning last layer(’last’), chain-thaw, gradual unfreezing (’freeze’) 등등의 효과를 확인. ‘Discr’, ‘Stlr’ 등의 효과를 확인 추가적으로, Strl을 떠올림에 있어서 영향을 받았던 aggressive cosine annealing schedule (’Cos’)도 적용해봄.
그 결과, 제안하는 기법이 좋은 효과를 얻는다는 것을 보여줌. (over engineering 한 만큼 성능의 이점을 얻음을 보여준 느낌)
Classifier fine-tuning behavior
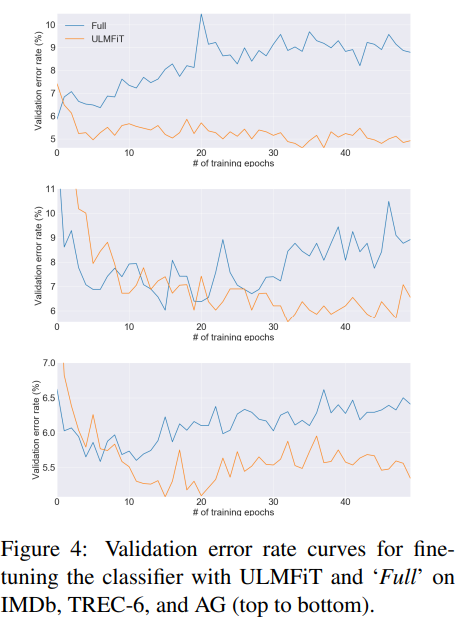
저자들은 모델의 fine-tuning behavior를 조금 더 잘 이해하기 위해, fine-tung 하는 과정에서 ULMFiT와 ‘Full’의 validation error를 비교하는 실험도 수행했다고 하네용. 모든 dataset에서 fine-tuning the full model은 lowest error를 초기에 부여 주었다고 합니다.
그다음, full model의 erorr는 model이 overfitting을 시작함에 따라 증가하였고, pretraining으로 capture했던 지식이 슬슬 잊혀졌다고 합니다.
이와 대조적으로!! ULMFiT는 fine-tuning 과정 중에서도 performance가 유지되는 것을 볼 수 있었다고 합니다. 신기하네요.
Impact of bidirectionality
forward and backwards LM classifier를 사용할 경우, 0.5~0.7의 성능 향상이 있었다고 함. IMDB에서는 5.30에서 4.58까지 test error를 크게 줄였다고 보고함.
Discussion
저자들이 ULMFiT가 SOTA 성능을 달성한다는 것을 보여주었다고 함. 저자들은 LM fine-tuning은 기존의 transfer learning 접근들에 비교하면 꽤나 유용할 것이라고 믿는다고 함. 특히 a) NLP for non-english languages, b) new NLP tasks where no SOTA architecture exists c) limited amounts of labeled data가 있는 태스크들
transfer learning and 특히 fine-tuning for NLP가 under explore되어 있는 상황에서, 많은 미래의 연구 방향들이 가능할 것 같다고 함.
LM은 또한 multi-task learning fashion 혹은 enriched with additional super vision e.g. syntax-sensitive dependencies to create a model에 유효할 것이라고 함.
Conclusion
저자들은 ULMFiT라고 하는, 어떤 NLP task에도 적용이 가능한, 효과적이고 극단적으로 sample 효율적인 transfer learning method를 제안했다고 함.
또한, 저자들은 catastophic forgetting을 방지하기 위한, 그리고 다양한 range의 task들에 대해 강건한 학습이 가능한 몇몇 새로운 fine-tuning technique들을 제안했다고 함
저자들의 기법은 기존의 transfer learning기법의 성능을 상당히 뛰어넘었으며, 6개의 표현적인 text classification task들에 대해서 SOTA를 달성했다고 합니다.
Appendix
'Reinforcement Learning > 강화학습 도서 및 강의' 카테고리의 다른 글
| [CS 330 - Lec 2] Multi-Task Learning (2) | 2022.10.03 |
|---|---|
| [CS 330 - Lec 1] Deep Multi-Task and Meta-Learning (0) | 2022.10.01 |
| [CS 330 - Lec 2] optional reading paper 단순 정리 - (Multi-Task Learning Using Uncertainty to Weigh Lossesfor Scene Geometry and Semantics) (0) | 2022.09.26 |
| 7장 강화학습 심화 3: 아타리 (0) | 2020.10.04 |
| 6장 강화학습 심화 2: 카트폴 (0) | 2020.10.03 |