가짜연구소 5기 멀티태스크메타러닝-초읽기 아카데믹 러너 활동을 통해 위의 강의를 듣게 되었습니다.
해당 스터디 활동의 조건은, 스터디에 참여하지 않은 사람들도 공부를 함께 할 수 있도록 하는 것이 원칙 중 하나기에, 스터디 과정 내 요약한 강의 요약본을 포스팅하게 되었습니다. 부족한 점이 있겠지만, 재미있게 봐주시면 감사하겠습니다!
Editor: 백승언
강의 슬라이드 링크: http://cs330.stanford.edu/fall2020/slides/cs330_intro.pdf
강의 링크: https://www.youtube.com/watch?v=0KWT9wIYoF8&list=PLoROMvodv4rOxuwpC_raecBCd5Jf54lEa
목차
Plan for today
Multi-task learning
Model
Objective
Optimization
Challenges
Plan for today

이번 강의에서는 Multi-Task(MT) learning을 주로 다루며, transfer learning의 basic에 대해서도 다소 다룬다고 하심.
MT learning에 대해서는 문제 정의, model, objectives, optimization 등에 다루고, 그다음 case study들에 대해서 다룬다고 하심. (이번 리뷰에서, case study는 제외했습니다!)
- Youtube의 recommender system 등
Multi-task learning

MT learning에 대해 다루기 전에, 먼저 이후 강의에서도 사용할 notation에 대해서 먼저 정리해 주심.
- x: input, y: output or label
- 이미지, 텍스트 등등에 대해 사례를 들어 재밌게 설명해 주심
- theta: parameters of neural network
- neural network는 f_theta(y|x)로 표현!
- Dataset D: input output pair
- L: loss function

또한, task는 무엇인지에 대해서 다시 formal하게 정의해주심.
- A task: data set의 분포인 p_i(x), x에 대해 추론된 y의 분포인 p_i(y|x), 특정 task i에 대한 loss function L_i가 있을 때, task는 그것들의 집합으로써 정의됨.
- T_i := {p_i(x), p_i(y|x), L_i}
- 또한, task별로 training data set D_i^tr, D_i^test에 대해서도 notation을 알려주심. D_i^tr은 D_i로 편하게 쓰겠다고 하심!
examples of multi-task problem에 대해서도 설명해주심
- Multi-task classification
- 오른쪽 위의 per-language handwriting recognition과 같은 task들의 경우, 모든 task의 loss function이 cross entropy로 동일.
- spam filter의 경우도, L_i는 동일. 하지만 p(x)와 p(y|x)가 다름.
- Multi-label learning
- loss function L_i, p_i(x)는 동일. 하지만, p(y|x)가 다름. 이것에 대한 예시로, scene understanding을 예제로 설명해주심.
- 예제로 들어주신 scene understanding의 경우, 하나의 사진에서 instance segmentation, depth prediction 등 여러 task에 대한 label이 주어지고, 사진 하나에 대해 각 task들을 모두 예측/분류하는 것이 목표인 multi-task.
- L_i가 동일하다고 표현하신 이유는, task별 loss function들을 weight하여 합쳐서 사용했기에 그런 것 같음.
- 그러면, 언제 L_i가 task에 따라 달라질 수 있는가?
- mixed discrete, continuous labels across task ⇒ 이해 정확히 안 됨
- multiple metrics that you care about
- spam filter의 경우, 해당 mail이 spam인지 ham인지
- 추천 시스템의 경우, 유저의 개인별 만족도 등이 metric이 되는 경우
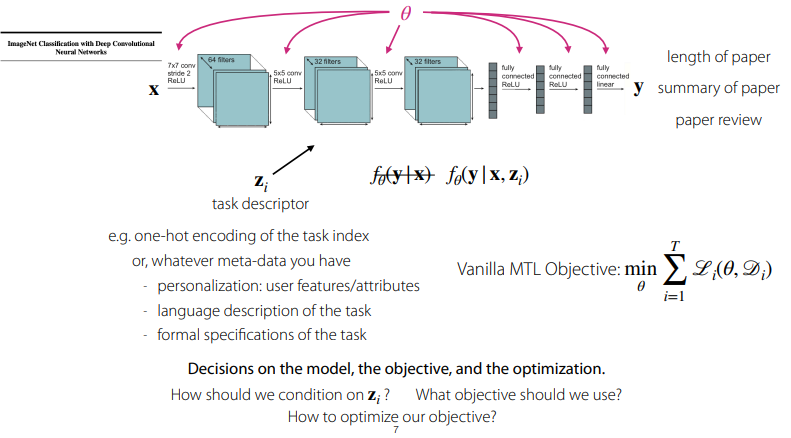
model을 어떻게 학습하는가? task descriptor z_i를 통해 task들이 condition될 수 있다는 것을 가정하고 학습을 수행한다고 하심.
- model의 input으로 task descriptor z_i를 입력받아서 model이 어떤 task를 해야 하는지 알려주는 컨셉
- 이러한 z_i는 task의 개수에 따라 단순히 one-hot encoding으로 사용할 수도 있고, user혹은 language별 meta-data 등이 될 수 도 있다고 하심
또한, Vanilla MTL objective function에 대해서 말씀하심. theta에 대해서, 모든 Loss L_i들을 각자의 task data set D_i에 대해 계산하여 합친 후, 최소화시키는 것.
이 슬라이드 이후에는, the model, the objective and the optimization 기법들에 대해서 설명하고, 어떻게 z_i를 조건화하는지, 어떤 objective function을 사용해야 하는지, objective function을 어떻게 최적화해야 하는지에 대해서 말씀한다고 하심
Model
How should the model be conditioned on z_i?
what parameters of the model should be shared?
model이 어떻게 task에 대해서 condition될 것인가?
⇒ 기본적으로, z_i를 one-hot task index라고 가정해보자!
그러면, 어떻게 이런 z_i를 share할 것인가?
Conditioning on the task
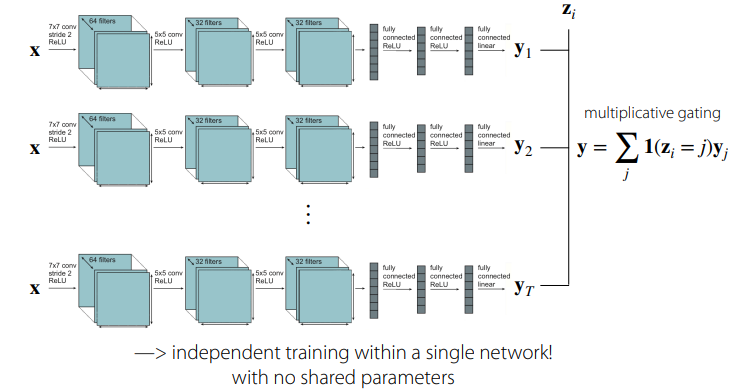
각 task별 model들은 독립적으로 학습시키고, 마지막에 gating 방식으로 하여 z_i를 사용하는 첫 번째 컨셉. 각 모델은 각기 다른 weight들로 수렴하도록 학습을 하게 됨.

이전의 컨셉과 대척점에 있는 컨셉으로써, 단지 z_i를 거의 마지막 혹은 middle 쪽에 더해줌으로써, 각기 다른 task들이 모든 parameter들을 share하는 컨셉.
- z_i가 one-hot이라면, z_i에 바로 따라오는 weight의 경우, task별로 0 혹은 1이 곱해지기 때문에, 이 친구는 share에서 예외다! 라는 설명을 해주심
An alternative view on the multi-task architecture

위의 컨셉과는 다른 방법으로써, 모델의 parameter theta를 shared parameter theta^sh와 task-specific parameter theta^i로 나누는 컨셉을 설명해주심
몇몇 일반적인 conditioning 방법들에 대해서 설명을 해주심
Conditioning examples

z_i를 input 혹은 중간의 정보에 concatenate하거나, 더하는 케이스. 이 두 가지는 정확히 같은 방법인데, 그 이유는 아래 그림처럼 z_i에 w_(z_i)를 곱하고 더하는, 일련의 계산 과정이 동일하기 때문이라는 것을 설명해주심.

multi-head architecture: shared representation을 입력받은 후, task-specific layer들로 분기하는 형태의 구조.
multiplicative conditioning: z_i가 더해지면, 이를 linear layer를 통과시킨 후, input의 representation과 곱하는 형태의 구조.
- ⇒ 이게 good idea인 이유는, adding, concatenating보다 더욱 표현력이 좋을 수 있기 때문(DNN이 universal appriximate estimator라는 것을 언급).
- 또한, 앞서 언급된 independnet network, independent head의 일반화된 형태라는 것을 언급해주심
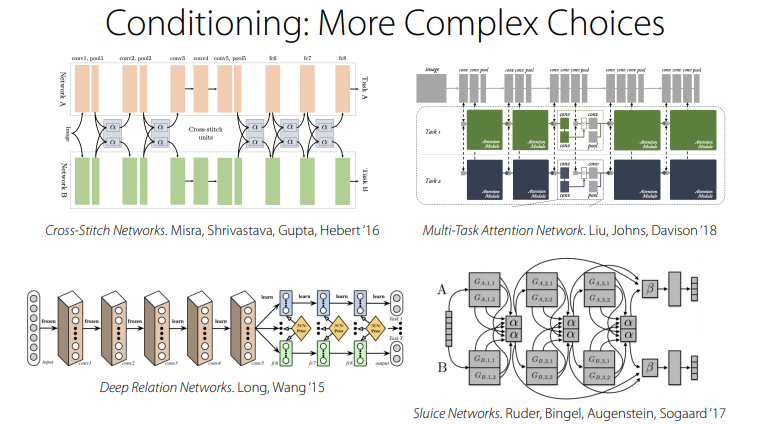
추가적으로, 핀 교수님은 복잡한 conditioning example중의 일부를 가져와서 소개해주심. 어질어질하군용
불행하게도, 이러한 설계들은 1) 문제에 의존 적이고, 2) 연구자의 직관이나 지식에 의존적이며, 3) 과학보다는 art에 가까운 측면을 가지고 있다고 하심
Objective
How should the objective be formed?

연구자들은 종종 vanilla MTL objective function을 그대로 사용하기보다는, task별로 weight을 다르게 주는 것을 원했다고 합니다. (맨 위 왼쪽 식 ⇒ 오른쪽 식)
그러면, “task별로 이러한 weight들을 어떻게 선정할 것인가?”가 MTL에서의 objective function을 설계하는 데 있어 핵심적인 질문이 된다고 합니다.
이를 manually tuning할 수도 있지만, 이는 좋은 방법이 아니라고 하심. 그러면서 이러한 weight들을 자동으로 조정하는 방법에 대해서 소개를 해주심
- various heuristic ⇒ gradients들이 simillar magnitude를 가질 수 있게끔 weight을 정해주는 방법(ICML 2018)
- task uncertainty를 사용하는 방법 ⇒ 특정 task의 uncertainty가 크다면, 해당 task의 uncertainty를 작게 만들 수 있도록 w_i를 튜닝하는 방법..! (CVPR 2018)
- pareto optimal solution을 향해, 점진적으로 개선하는 것 (Nips 2018)
- worst-case task loss를 최적화하는 것. (or task robustness or for fairness)
Optimization
How should the objective be optimized?

설계된 objective를 어떻게 최적화할 것 인지에 대한 주제도 간단히 다룸. 먼저, basic version에 대해!
- 먼저, task가 몇 개 안 된다면 모든 task에서 data를 sampling할 수도 있을 것이고, task가 많다면 task별로 mini-batch datapoints를 sampling할 수도 있을 것임.
- 이에 대해서 loss를 계산하고, loss를 통해 gradient를 계산 ⇒ backprogate, ⇒ applying gradient!
- 이때, loss의 scale이 동일할 수 있게, task별 loss에 weight을 곱해주는 과정이 필요할 수 도 있다는 얘기를 해주심
이다음 장부터는, MTL에서의 challenging components에 대해서 다룬다고 하심.
Challenges

첫 번째로, negative transfer에 대해서 언급. 가끔은 independent network가 좋더라… Why?
- 먼저, 최적화 과정에서의 어려움이 있기 때문. cross-task interference가 gardient를 어지럽힐 수 있고, 각 task들의 learning rate가 다를 수도 있다는 점을 언급해주심
- 또한, limited representational capacity를 언급해주심. multi-task network는 종종 single-task network에 비하여 더욱 큰 capacity를 요구한다고 하심
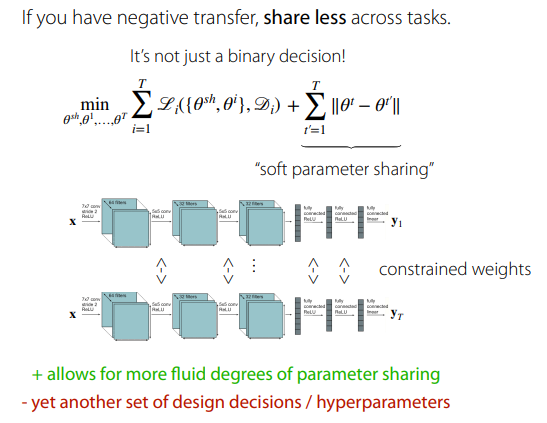
만약, negative transfer 현상이 발견되면, task별 shared parameter를 직접적으로 sharing하는 것이 아니라, soft하게 sharing하는 방법을 제안해주심.
- soft sharing의 경우, 저는 최적화 문제에서의 hard constraint / soft constraint와 비슷한 느낌으로 이해가 되는 것 같습니다.

두 번째 어려운 요소로써, overfitting에 대해서 언급하심. 이는 충분히 sharing하지 않기 때문에 발생하는 문제라고 하네요..! MTL은 regularizing의 하나라고 간주할 수 있다고 하시며, 이를 해결하기 위해서는 sharing하는 parameter의 양을 늘리면 좋다고 추천해주셨습니다.
혹시나 끝까지 봐주신 분이 계시다면, 봐주셔서 감사하다는 말씀을 드리며 마무리 짓겠습니다!