가짜연구소 5기 멀티태스크메타러닝-초읽기 아카데믹 러너 활동을 통해 위의 논문을 읽게 되었습니다.
노션을 복붙 해오니 영 마음에 들진 않지만..! 제가 주로 다루는 분야가 아니기에, 가볍게 정리하는 느낌으로 가져가볼까 합니다.
Multi-Task Learning Using Uncertainty to Weight Losses for Scene Geometry and Semantics
Abstract
- 다양한 딥러닝 application들은 multi-task learning으로부터 이점을 얻을 수 있다.
- 이 논문에서, 저자들은 이러한 system들의 성능이 각 task들의 loss 사이의 상대적 weighting에 강하게 의존한다는 것을 보여준다고 함
- 저자들은 각 태스크들의 불확실성을 동분산적으로 고려함으로써 다중의 loss function에 weight을 줄 수 있는 접근 방법을 제공한다.
- 이는 classification과 regression setting 모두에서, 다양한 단위와 scale을 가지는 various quantity들을 동시에 학습하는 것을 가능하게끔 한다고 함
- 저자들은 그들의 모델이 per-pixel depth regression, semantic 그리고 instance segmentaion등을 학습하는 것을 보여주었다고 함.
- 여기서 놀라운 점은, 저자들의 모델이 multi-task weigithing을 학습했을 뿐만 아니라, 각각의 태스크를 학습한 개별 모델 들의 성능을 outperform 했다는 것이라고 함.
Introduction
Multi-Task(MT) learning은 shared representation으로 부터, multiple 목적들을 학습하여, 예측의 정확도와 학습의 효율성을 개선하는 것에 목적을 둔다고 함
MT leanring은 다양한 분야에서 좋으며, 저자들은 visual scene understanding 분야에서 MT learning을 연구했다고 함.
Scene understanding은 geometry와 semantics of the scene을 동시에 학습해야만 한다고 함
⇒ 다른 unit, scale등을 가지는 다양한 regression, classification 문제를 학습해야 하는 흥미로운 MT learning 문제임을 강조
또한, visual scene understanding에서의 Mt learning은 중요한데, 그 이유는 robotics 등에서 사용될 때, long computation run-time이 금지되기 때문이라고 함.
⇒ 모든 task를 하나의 모델에서 하게 되면, computation time을 감소시킬 수 있을 뿐만 아니라, 이러한 시스템들이 real-time으로 동작할 수 있게 해 준다고 함
다양한 task를 동시에 학습하고자 할 때의 이전의 접근법은 단순히 loss들을 weighted sum하는 방법을 사용했다고 함.
그러나, 저자들은 MT model의 성능이 각 task들의 loss사이의 weighting의 적절한 선택에 강하게 의존한다는 것을 보여주고, 이러한 manual tuning은 좋지 않다는 얘기를 함.
이 논문에서, 저자들은 homoscedastic uncertainty를 이용해서, 다양한 목적함수 들을 동시에 학습하기 위한 multiple loss function들의 compining의 좋은 방법을 제안했다고 함.
저자들은 homoscedastic uncertainty를 task-dependent weighting으로 번역 하고, 다양한 regression과 classification task를 균형 있게 학습할 수 있는, 주된 MT loss function이 어떻게 유도되는지를 보여주었다고 함.
⇒ 또한, 이렇게 weigthing들을 최적으로 학습할 수 있는 저자들의 방법은, 각 task를 individually 학습 하는 것에 비하여 더 좋은 성능을 내었다고 함.
구체적으로, 저자들은 scene geometry와 3개의 semantic task 들을 학습할 수 있는 저자들의 method를 보여주었다고 함.
- 저자들은 pixel level에서 object를 분류하였음 (semantic segmentation)
- 저자들은 instance segmentation이라고 하는, image 내에서의 각 individual object의 seperate mask를 segmenting 하는 어려운 태스크를 수행함
- 마지막으로, 저자들의 모델은 pixel-wise metric depth를 예측했다고 함. 이는 굉장히 어려운 태스크라고함.
그리하여, 한 장의 monocular input image가 주어지면, 저자들의 시스템은 먼저, semantic sgmentation을 제공하고, metric depth를 추정하고, instance level을 추정한다고 함.
다른 MT learning을 수행한 비전 관련 모델들이 보여주어 온 것과 달리, 저자들은 semantic들과 geometry를 어떻게 함께 학습하는지를 보여준다고 함.
마지막으로, 저자들은 MT learning의 shared representation을 사용하는 것이 다양한 metric의 성능을 개선하는 것과, 모델을 효율적으로 학습할 수 있다는 것을 보여주었다고 함.
요악하면, 해당 논문의 key contribution들은 다음과 같다고 함.
- homoscedastic task uncertainty를 이용해서, 새롭고 원칙적인, 다양한 quantity들과 unit들에 대해 다양한 classification과 regression losse들을 동시에 학습할 수 있는 multi-task loss를 설계
- semantic segmentation, instance segmentation 그리고 depth regression을 위한 통합된 아키텍쳐를 설계
- multi-task DL에서의 loss weighting의 중요성을 보여주고, 어떻게 이것이 separately trained model에 비해 우수한 성능을 얻는지를 보여줌.
관련 연구들에 대해서 언급한 뒤…
더욱 중요한 것은, 모든 이전의 기법들은 naive weighted sum of losses를 사용해서 multiple task들을 동시에 학습했다는 것에 대해서 강조.
⇒ 해당 연구에서 저자들은 homoscedastic task uncertainty를 이용해서, 다양한 목적함수 들을 동시에 학습할 수 있는, multiple loss funcdtion들을 combining하는 방법에 대한 원칙적인 방법을 제공하였다고 함.
Methodology
Multi task learning with Homoscedastic Uncertainty
- MT leaning은 중요하다! 단순한 접근은 each individual task에 대한 loss들의 합을 weighted linear sum 하는 것이다 라는 것을 보여줌.
- 또한, 다양한 이전 연구들을 인용하며, 이것이 주된 접근이었다는 것에 대해서 설명을 수행함.
- 이 방법은 여러 이슈가 있는데, 일단, 명백하게 모델의 성능이 weight selection에 너무 극심하게 예민하다는 것을 먼저 언급함. 또한, 이를 tuning하는 것은 너무나 비싼 과정이라고 함.
⇒ 그러므로, optimal weights를 학습할 수 있는 더욱 편리한 접근법을 찾는 것이 필요하다고 강조함.
2. Homoscedastic uncertainty as task-dependent uncertainty
Bayesian modeling 에서, uncertainty는 두 개의 주된 타입으로 모델링 될 수 있다고 함.
- Epistemic uncertainty: 모델 내에서의 불확실성으로, 모델이 data의 부족으로 인해 무엇을 모르는지에 대해 알려줄 수 있다고 함.
- Aleatoric uncertainty: 우리의 data가 설명할 수 없는 정보에 대해, 불확실 성을 capture할 수 있다고 함.
- 이는 또한, data-dependent or heteroscedastic uncertainty와 task-dependent or homoscedastic uncertatinty로 분류할 수 있다고 함.
- Data-dependent or heteroscedastic uncertainty: input data와 예측된 model output에 의존적인 불확실성?
- Task-dependent or homoscedastic uncertainty: input data에 의존적이지 않은 불확실성. 이는 모델 출력이 아니라, 모든 입력 데이터에 대해 일정하게 유지되며, 다른 task들 사이에서 변하는 양. 따라서, task-dependent uncertainty라고 할 수 있다고 함
multi-task setting에서, 저자들은 task uncertainty가 task들 사이의 relative confidence를 capture 할 수 있음과, regression or classfication task의 내재된 불확실 성을 반영할 수 있는 것을 보여준다고 함.
또한, 이는 trask의 표현 or unit or measure에 의존적인 것을 보여주나 봄(중요한 듯)
저자들은 multi-task learning 문제에서 loss를 wighting 하기 위한 기초로써 homoscedastic unceretainty를 사용할 수 있음을 제안한다고 함.
- Multi-task lidelihoods
저자들은 gaussian likelihood with homoscedastic uncertainty를 최대화하는 것을 기반으로 하여 multi-task loss function을 유도하는 것을 이 장에서 보여준다고 함.
regression task들에서, 저자들은 Gaussian with mean given by the model output으로써 likelihood를 정의했다고 함. sigma는 observation noise scalar라고 한다네요…
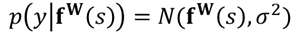
classification task에서, 연구자들은 종종 model output을 softmax function을 통해서 squash한다고 합니다. 그리고, probability vector를 결과로부터 sampling 한다고 합니다.

multiple model ouput의 경우, 연구자들은 종종 likelihood를 몇몇 충분한 통계치들이 정해질 경우, output들의 factorise로써 정의한다고 합니다. 그리고 다음과 같은 multi-task likelihood를 얻는다고 합니다.
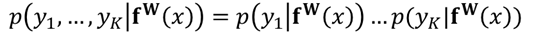
- In maximum likelihood inference, 저자들은 model의 log likelihood를 최대화한다고 합니다. 예를 들어 regression에서, log likelihood는 다음과 같이 서술할 수 있다고 합니다.
- 이는 $\sigma$ 라고 하는 output들이 얼마나 많은 noise를 가지고 있는지를 capture할 수 있는 model의 obserevation noise parameter 를 표준편차로 가지는 gaussian log likelihood라고 하네요
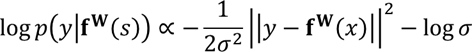
그러면, 저자들은 model parameter W와 observation noise parameter $\sigma$를 이용해서 model에 따른 log likelihood를 maximise 할 수 있다고 하네요.
- Regression의 경우, 저자들의 모델의 output이 two vector $y_1$, $y_2$로 구성되어 있다고 가정하게 되면, 불확실성 p는 다음과 같이 계산할 수 있다고 합니다.
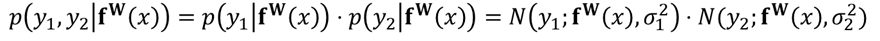
이는 minimisation objective L(W,sigma_1,sigma_2) for thier multi-output model을 다음과 같이 정의해준다고 합니다.
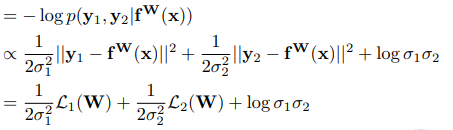
이때, 저자들은 first output variable 의 loss를 다음과 같이 사용했다고 하며, L2(W) 역시 동일하다고 합니다.
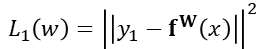
저자들은 위의 sigma_1, sigma_2로 이뤄진 objective를 최소화하는 것을, 데이터에 기반하여 L1(w) 및 L2(w)의 상대적 가중치를 적응적으로 학습하는 것으로 해석했다고 함.
$\sigma_1$이 증가함에 따라, L1(w)가 줄어든다는 것을 얘기함. 이와 반대로, $\sigma_1$이 감소하면, L1(w)이 증가함을 얘기함. 그런데, 마지막 항은 그와 반대로 움직임. ⇒ regularaizer의 역할을 수행
- Classification의 경우, 조금 더 흥미롭다고 얘기함. 저자들은 classification likelihood를 softmax를 이용해 squash 했다고 함.
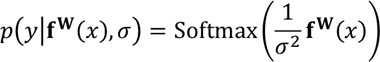
이는 boltzmann distribution으로 해석할 수 있다고 함. sigma^2의 역할은 temperature. 이 출력의 log likelihood는 다음과 같이 쓸 수 있다고 함.
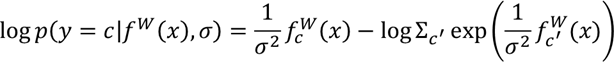
f^W_c(x)는 c’th element of the vector f^W(x)}라고 함.
- 마지막으로, continuous output y_1과 discrete output y_2로 이뤄진 multiple output을 가정하였을 때의 손실 함수 L(W,sigma_1, sigma_2)에 대해서 알아봅시다
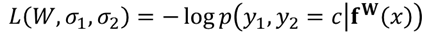
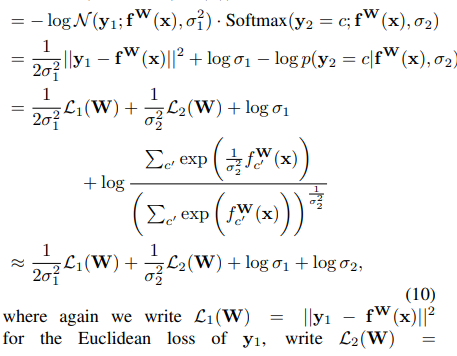

여기서, 마지막 term의 경우, 다음의 가정을 두어서 log(sigma_2)가 튀어나온 것이라고 합니다.
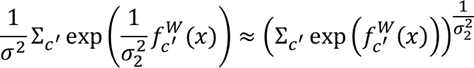
다양한 조합의 regression & classification task에서의 loss는 위의 결과들을 확장하여 손쉽게 얻을 수 있다고 합니다.
Scene understanding model
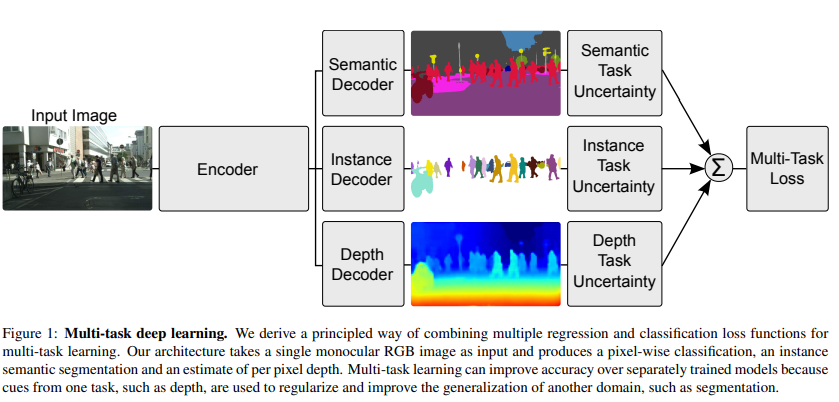
semantic 들과 geometry를 이해하기 위해, 저자들은 fixel level에서 regression and classification output들을 학습할 수 있는 아키텍쳐를 제안했다고 함.
저자들은 convolutional encoder-decoder network 구조를 차용했으며, encoder들은 shared representation을 만들어 내고, task-specific convolutional decoder들이 그 뒤를 따른다고 자신들의 아키텍쳐를 설명함.
그다음, 저자들은 network를 각각의 task에 대해 separate decoder들로 나누었다고 함. decoder의 목적은 shared feature로부터 output으로의 mapping을 학습하기 위한 목적이라고 함.
- Semantic segmentation
pixel-wise class probability를 학습하기 위해, cross-entropy loss를 사용. 각 mini-batch에서 semantic label의 pixel별 loss를 평균
2. Instance segmentation
regression appraoch를 사용. object parts로부터 Hough votes를 사용하여 instance들을 식별하는 [28]에서 영감을 받았다고 함. 이를 DL로 바꾼 것.
pixel’s instance i_n의 중심 포인트인 각 pixel coordinate c_n에 대해 instance vector \hat x_n을 학습하였다고 함.?? i_n=\hat x_n+c_n
3. Depth regression
또한, 다음의 loss function을 사용해서 저자들은 pixel-wise metric inverse depth를 이용하는 supervised label을 훈련
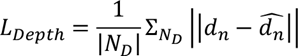
그들의 아키텍쳐는 inverse depth $\hat d_n$을 추정하는데, 왜냐하면, 이는 하늘과 같은 infinite distance를 표현할 수 있기 때문이라고 함.
Experiments
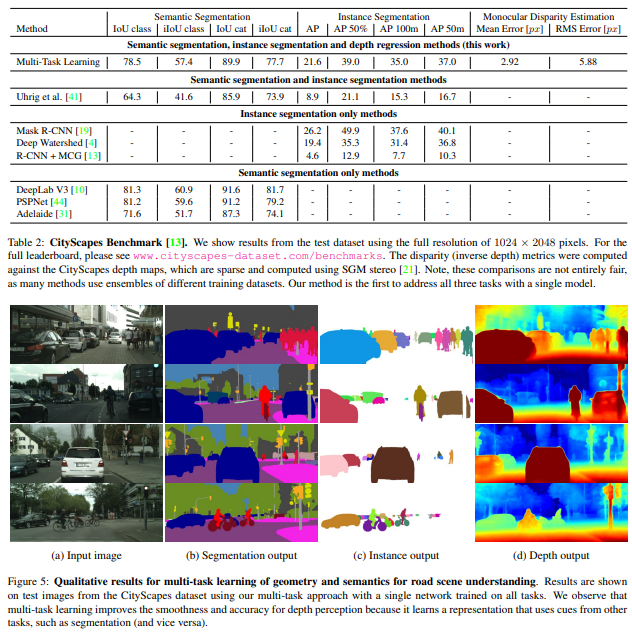
Dataset으로는 CitySpaces를 활용. 이는 road scene understanding을 위한 large dataset이라고 하네용.
- 저자들은 여러 단순한 multi-task loss들과 비교를 수행함
- uniform weighting 의경우, 좋지 않은 성능을 보여줌
- 최적의 weight을 근사하는 경우(hand tuning)에는 task 숫자가 많아지면 비용이 너무 올라간다는 문제가 존재.
- 저자들이 제안한 방법은 fine-grained grid search를 통해 얻은 optimal weight에 비하여 높은 성능을 보여주었다고 함.
Conclusion
저자들은 multi-task learning problem에서, 가장 중요한 것이 correctly weighting loss term이라는 것을 보여주었다고 함.
또한, 저자들은 homoscedastic uncertainty가 weight losses의 효율적인 방법임을 보여주었다고 함.
저자들은 weight initialization에 robust한, data로부터 자동으로 weighting하는 것을 학습 가능한 principled loss function을 유도해 냈다고 함.
저자들은 이를 이용하면 unified architecture에서 3개의 scene understanding task의 성능이 개선되는 것이 가능하다는 것을 보여줌
저자들은 task-dependent homoscedastic uncertainty가 각각의 task를 분리하여 학습하는 모델에 비하여, model의 표현과 각 태스크의 성능을 개선할 수 있음을 보여주었다고 함.
There are many interesting questions left unanswered. Firstly, our results show that there is usually not a single optimal weighting for all tasks. Therefore, what is the optimal weighting? Is multitask learning is an ill-posed optimisation problem without a single higher-level goal?
A second interesting question is where the optimal location is for splitting the shared encoder network into separate decoders for each task? And, what network depth is best for the shared multi-task representation?
Finally, why do the semantics and depth tasks outperform the semantics and instance tasks results in Table 1?
Clearly the three tasks explored in this paper are complimentary and useful for learning a rich representation about the scene.
It would be beneficial to be able to quantify the relationship between tasks and how useful they would be for multitask representation learning.
'Reinforcement Learning > 강화학습 도서 및 강의' 카테고리의 다른 글
| [CS 330 - Lec 1] Deep Multi-Task and Meta-Learning (0) | 2022.10.01 |
|---|---|
| [CS 330 - Lec 2] optional reading paper 단순 정리 - (Universal Language Model Fine-tuning for Text Classification) (0) | 2022.09.26 |
| 7장 강화학습 심화 3: 아타리 (0) | 2020.10.04 |
| 6장 강화학습 심화 2: 카트폴 (0) | 2020.10.03 |
| 5장 강화학습 심화 1: 그리드월드와 근사함수 (0) | 2020.10.02 |