가짜연구소 5기 멀티태스크메타러닝-초읽기 아카데믹 러너 활동을 통해 위의 논문을 읽게 되었습니다.
노션을 복붙 해오니 영 마음에 들진 않지만..! 제가 주로 다루는 분야가 아니기에, 가볍게 정리하는 느낌으로 가져가 볼까 합니다.
One-shot Learning with Memory-Augmented Neural Networks
Abstract
- 최근, DNN의 적용 사례들에도 불구하고, 아직 까지도 지속적인 어려움을 주고 있는 컨셉 중 하나는 “one-shot learning”이라고 함.
- 전통적인 gradient 기반의 네트워크들은 학습을 위해 많은 데이터와 함께, 종종 광범위한 반복 적인 학습을 요구한다고 함. 모델이 새로운 데이터를 마주쳤을 때, catastrophic interference 없이 새로운 정보를 적절히 통합하기 위해서는, 그들의 파라미터를 비효율적 이게도, 다시 학습해야만 한다고 함.
- NTM과 같은 augmented memory capacities를 가지고 있는 구조는 새로운 정보를 빠르게 encode and retrieve 할 수 있는 능력을 제공하고, 그러므로 conventional model들의 단점들을 잠재적으로 피해갈 수 있다고 함.
- 이 논문에서, 저자들은 memory-augmented neural network가 빠르게 새로운 데이터와 친해지고, 단지 몇 샘플들 만으로도 정확한 예측을 하기 위해, 이 데이터들을 활용하는 능력을 보여준다고 함.
- 또한, 저자들은 추가적인 memory location-based focusing mechanism을 이용하는 이전의 기법들과 달리, memory contents에 초점을 맞춘 external memory에 접근할 수 있는, 새로운 기법을 제안한다고 함.
Introduction
DL의 현재의 성공은 gradient 기반의 최적화를 high-capacity model들에 적용하는 능력에 달려 있다고 함.
- 이러한 접근은 많은 대규모의 지도학습 태스크들에서 인상적인 결과들을 달성해 왔다고 함. (image classficiation, speech recognition, game 등등).
명백히, 이러한 태스크에서의 성능들은 large data set에서의 광범위하고 점진적인 학습 이후에 평가되었다고 함.
- 대조적으로, 많은 흥미로운 문제들은 적은 양의 데이터로부터 빠르게 inference하는 것을 필요로 한다고 함. “one shot learning”에서의 한계로, single observation들은 행동의 급격한 변화를 가져와야 한다고 함?
이러한 종류의 유연한 적응은 human learning의 유용한 측면이며, motor control로부터 추상 컨셉 획득??까지 다양하게 나타난다고 함.
- 하나 혹은 둘 정도의 문맥들 만으로 새로운 세계의 full range of applicability를 추론해내는 등, 몇 조각의 정보들로부터 추론해낸 정보를 기반으로 새로운 행위를 만들어 내는 것은 현재의 machine intelligence가 도달한 것을 아득하게 뛰어넘는 무언가로 남겨져 있다고 함.
- 또한, 이는 deep learning에겐 특히나 벅찬 도전 요소를 제공한다고 함
몇몇 example들이 하나씩 주어지는 상황에서, gradient-based solution은 해당 순간마다 data로부터 parameter들을 완전히 재 학습해야 한다고 언급.
- 이러한 상황에서, 위험도의 관점에서 non-parametric method들이 종종 더욱 적합한 것으로써 여겨진다고 함. (이 부분은 실험을 통해 보여줌)
그러나, 이전의 작업들은 sparse data로부터 빠른 학습에 도달하기 위한 meta-learning이라는 개념의 하나의 잠재적인 전략을 제안했습니다.
- 비록 해당 term은 다양한 sense로(뉘앙스 같음) 사용되어 왔지만, meta-learning은 일반적으로 agent가 두 단계로 학습하며, 각 단계는 different time scale과 연관되어 있는 시나리오를 말한다고 합니다. ⇒ 큰 데이터로 주구장창 배우고, 몇몇 데이터로 few shot 하는 느낌의 얘기 일까용?
빠른 학습은, ‘태스크 내에서’ 발생하는데, 예를 들면 특정 데이터셋 내에서 정확하게 분류하는 방법을 학습할 때 발생합니다. 이 학습은 ‘태스크 전반에 걸쳐’ 점진적으로 축적된 지식에 따라 진행이 되며, 이는 task의 구조가 타겟 도메인에 따라 변하는 방식을 capture합니다.
- 이러한 two-tiered 구조가 주어지면, 이러한 형태의 meta-learning은 종종 learning to learn으로 묘사된다고 합니다.
meta-learning과 관련된 능력이 있음을 보여온, memory capacity를 가지는 neural network들이 제안되어 왔다고 합니다(Hochreiter et al, 2001). 이러한 신경망들은 weight update를 통해 그들의 bias를 shift할 뿐만 아니라, memory내의 cache representation을 빠르게 학습하여 출력을 조절한다고 합니다.
- 예를 들어, 메타 학습을 위해 훈련된 LSTM들은 적은 수의 data sample들 만으로 never-before seen quadratic function들을 빠르게 학습할 수 있었다고 합니다. (Hochreiter et al, 2001)
memory capacity를 가지는 NN은 deep network내에서 meta-learning을 위한 유망한 접근 법을 제공한다고 합니다.
- 하지만, 구조화되지 않은 recurrent architecture에서의 내재적인 memory를 사용하는 특정 전략은, 새로운 정보가 rapily encoded 되기 위해서, 상당히 많은 양의 새로운 정보를 요구하기 때문에, 확장성이 있는 셋팅은 되지 않을 것 같다는 비판을 하는 것 같습니다… 너무 어렵게 쓰는데요..ㅠ
Scalable solution은 거의 적은 필요조건들을 가지고 있어야 한다고 주장합니다. 1) 정보는 안정적이고, element-wise로 접근이 가능한 형태로, 메모리에 저장이 되어야 합니다. (필요할 때 안정적으로 접근할 수 있어야 하며, 관련 정보의 조각들에 선택적으로 접근할 수 있어야 합니다.) 2) parameter들의 숫자는 memory의 size와 연관이 있으면 안 됩니다.
- 이러한 두 개의 특성은 LSTM류와 같은 기존의 memory architecture 내에서는 자연스럽게 발현되지 않는 특성이라고 함.
그러나, Neural Turning Machines(Graves et al, 2014), memory network(Weston et al, 2014)과 같은 최근의 아키텍처들은 이러한 요구 조건을 만족한다고 합니다.
- 그리고 또한, 이 논문에서 저자들은 meta-learing problem에 revisit 하며, higly capable memory-augmented neural network 관점으로부터 meta-learning problem을 setup 한다고 하네용.
- 또한, MANN은 external-memory equipped NN이라고 부르고, LSTM과 같은 memory-based architecture들을 “internal”로 퉁쳐서 부르겠다고 합니다.
저자들은 MANNs가 상당히 짧은 term과 긴 term의 memory demands를 수행하는 task들에서 meta-learning을 할 수 있는 능력을 보여 주었다고 합니다.
- 본 적 없는 Omniglot class들을 거의 사람과 같은 정확도로 분류해내는 데 성공하여 이런 것을 명백히 했다고 하네요.
더욱이, 저자들은 content로 접근 가능한 memory access module을 강조하였으며, NTM과 같은 추가적인 memory location을 사용하지 않았다고 합니다.
그러면, 같이 한 번 methdology와 실험을 보시죠!
Methodology
Meta-learning task Methodology
저자들은, 보통 하듯이 Dataset D들로부터 cost L을 최소화하는 parameter theta를 선택했다고 합니다. 그러나, meta-learning을 위해서는, 저자들은 expected leanring cost across a distribution of dataset p(D)를 감소시키기 위해 parameter를 선택했다고 합니다.
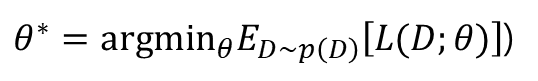
이를 달성하기 위해서는, 적절한 task setup이 매우 중요하다고 합니다. 저자들의 setup에서, task 혹은 episode는 some dataset D={d_t}^T_t=1의 제공을 포함한다고 합니다.
(중략)
궁극적으로, 이 system은 예측 분포 p(y_t | x_t, D_(1:t-1); theta)를 모델링하여, 각 time step에 대응하는 loss를 유도하는 것을 목표로 한다고 합니다.
이 task structure는 exploitable meta-knowledge를 통합한다고 합니다. meta-knowledge: 메타 학습 모델은 데이터 표현 또는 레이블의 실제 내용에 관계없이 데이터 표현을 적절한 label로 라벨링 하는 방법을 배우고, 이러한 표현을 예측하기 위한 적절한 클래스 또는 함숫값에 매핑하는 일반적인 전략을 사용한다고 합니다.
Memory-Augmented Model
Neural Turing Machines(NTM)
NTM은 MANN의 fully differentiable한 구현체라고 합니다. 이 모델은 read and writh heads들을 이용해 external memory module과 상호작용 하는, FF or LSTM과 같은 controller로 구성되어 있다고 합니다. NTM은 또한, external memory module에서 memory encoding and retrieval은 빠르다고 합니다.
- 이 능력은 NTM이 wiehgt update를 통한 long-term stroage와 external memory module을 이용한 shor-term strage가 모두 가능하기 때문에, meta-learning and low-shot prediction의 완벽한 후보가 될 수 있게끔 해준다고 하네요.
그래서, 만약 NTM이 types of representation을 memory에 place할 수 있고, 예측을 위해 이러한 표현들을 나중에 어떻게 사용할지 등에 대한 일반적인 전략을 학습할 수 있다면, 한 번밖에 못 봤던 data의 정확한 예측을 빠르게 만들어 낼 수 있는 능력을 사용할 수 있다고 함.
제안된 모델에서 사용하는 controller들은 LSTMs or FF network이 될 수 있다고 함. 제어기는 memory로부터 표현을 retreive하거나 place하는 등에 read write를 사용하는 external memory와 상호작용 한다고 함.
- input x_t가 주어지면, controller는 memory matrix M_t의 행에 접근할 수 있는 key k_t를 생산해내는 느낌.
- memory에서 retrive할 때, M_t는 cosine similiarity measure를 이용해서 addressed 된다고 함.
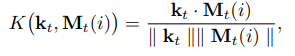
이는 read_weight vector w^r_t를 만들어낼 수 있다고 함.

더욱이, memory r_t는 weight vector를 통해서 retrive 된다고 합니다.

해당 메모리는 controller에서 classifier의 입력으로써 사용되고 next controller state의 입력으로써도 사용된다고 하는 것 같습니다.
Least Recently Used Access(LRU access)
이전의 NTM에서, memory들은 content와 location에 대해서 address되었다고 합니다. location-based addressing은 tape를 따라서 달리는 것 혹은 long-distance jumpts across memory하듯 iterative step을 촉진하는 데 사용되었었다고 하네요.
- 이 기법은 sequence-based prediction task에 장점을 가지고 있다고 합니다.
- 그러나, 이러한 aceess type은 sequence에 독립적인 정보를 가지고 있는 task에는 최적이 아니라고 합니다.
이러한 이유로!! writing to memory in our model은 새로이 디자인된 LRUA module을 포함하고 있다고 하네용
LRUA 모듈은 least used memory location이나 most recently used memory location에 memory를 write하는 pure content-based memory writer라고 합니다.
- 이 모듈은 information과 관계된 정확한 encoding을 강조하고, qure content-based retrival을 강조한다고 하네요 음?
- 새로운 정보는 recently encoded된 정보를 보존하면서, 거의 사용되지 않는 위치에 기록되거나, 마지막으로 사용된 위치에 기록되며, 이는 보다 최신의 관련성 있는 정보로 메모리를 업데이트하는 기능을 할 수 있다고 합니다.
이 두 개의 옵션의 차이는, 이전의 read weight들 사이의 interpolation, 그리고 weight의 scale에 따라 만들어진다고 하네용. 이러한 usage weight들은 각 time-step에 다음과 같은 prevous usage weights와 current read/write weights들을 이용해서 업데이트된다고 합니다.
- 이때, gamma는 decay parameter이고, w^r_t는 위에서 계산된다고 합니당. the least-used weights w^lu_t는 w^u_t를 이용해서 2번째 식으로 계산된다고 합니다. (이때, n은 memory의 number of reads와 같다고 합니다.)
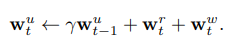

또한, write weights w^w_t를 얻기 위해, learnable sigmoid gate parameter가 previous read wiehts와 previous least-used weights를 convex combination 하기 위해 사용되었다고 합니다.
- 이때, sigma(.)이 sigmoid function이고, alpha는 scalar gate parameter라고 합니다. memory에 writhe를 하기 이전에, least used memory location은 w^u_(t-1)로부터 계산되고, 이는 set to zero가 된다고 합니다.
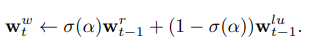
writing to memory는 write weithgs의 vector를 계산한 이후에 바로 일어난다고 하네요.
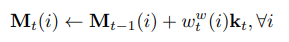
그래서, 메모리들은 zeroed memory slot에 write되거나, previous used slot에 write 된다고 하고, least used memory는 간단히 제거가 된다고 합니다.
Experimental Results
Data
두 개의 sources of data가 사용되었다고 합니다. classification을 위한 Omniglot, 그리고 regression을 위한 fixed hyperparameter를 가진 GP로부터 sampling된 functions.
Omniglot dataset은 클래스별로 예제가 많이 없는, 1600개 이상의 분리된 클래스로 이루어진 데이터 셋이라고 하며, MNIST의 transpose라고 불린다고도 합니다. overfiting의 risk를 줄이기 위해서, 저자들은 data augmentation을 사용했다고 합니다.
- model을 학습시킬 때에는 1200개의 original classes(with augmentations)의 데이터를 사용했으며, 나머지 423개의 classes(with augmentation)은 test experiment에 사용되었다고 합니다. 또한, 계산 시간을 줄이기 위해 image를 downscale 했다고 하네요.
Omniglot classification
class label을 one-hot vector 표현으로 하여 학습을 수행했다고 합니다. 100,000 episode의 학습 이후, network에게는 never-before-seen classes로 이뤄진 series of test episodes가 주어졌다고 합니다.
- 해당 모델은 two shot에서도 82.8%의 high classification accuracy를 보여주었다고 하며, fifth instance, tenth instance들을 보여줌에 따라 정확도가 94.9%, 98.1%에 도달하는 것을 보여주었다고 합니다.
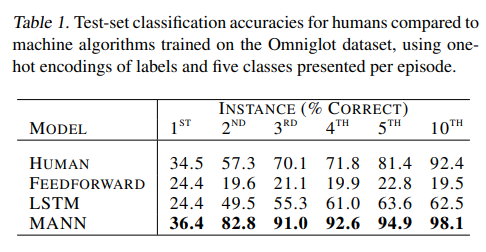
또한 조금은 복잡한 방식으로….ㅎㅎ 사람에게 유사한 task를 시킨 다음 사람이 수행한 결과와 MANN의 성능을 비교해 본 결과, 각 instance 들에서 사람을 뛰어넘는(surpass) 성능을 보여주었다고 합니다.
large one-hot vector를 이용하여 classifier의 wieht들을 학습하는 것은 scale이 증가함에 따라 점점 어려워지기 때문에, 클래스에 label을 지정하는 다른 접근 방식을 사용해, 주어진 에피소드에서 제공되는 클래스의 수를 임의로 늘릴 수 있다고 합니다.
- 이러한 새로운 label은 five character로 이루어진 string으로 구성되었다고 하며, 각 character는 5개 중 하나의 value를 가질 수 있게끔 설정했다고 합니다. {’a’, ‘b’, ‘c’, ‘d’, ‘e’} 허허…
- srting들은 one-hot vector로 표현된 후, concat되어 25 만큼의 길이를 가진 vector로써 사용되었다고 하네요. 이러면 3125개의 class를 표현할 수 있는데, omniglot이 1600여 개여서 이렇게 했다고 하는 것 같습니다.
제안하는 network가 이러한 class 표현을 이용해서 학습할 수 있는지 확인하기 위해, 실험을 다시 수행해 보았다고 합니다. 그랬더니, MANN with a standard NTM access module은 MANN with LRU access module에 미치지 못하는 성능을 명백하게 보여주었다고 합니다.

또한, 저자들은 set of baseline으로써 feed-forward RNN, LSTM and a nonparametric nearst neighbours classifier that used either raw-pixel input or features extraced by an autoencoder 등등을 고려했다고 합니다.
- autoencoder 기반 분류기의 경우, MANN보다 많은 parameter를 가질 수 있게 설정하였고, 3배의 augmented data를 통해 학습을 시켰다고 합니다. 그럼에도 불구하고 더 좋은 성능을 냈다고 하네요ㄷㄷ
- 또한, 도입부에서 언급한 것처럼, non-parametric approach인 kNN계열의 분류기가 gradient-based parametric model인 FF, LSTM 등등보다 더 좋은 성능을 낸 것도 재미있는 결과인 것 같습니다.
CURRICULUM TRAINING

episodes with fifteen classes에서의 one-shot classification task에서 성공을 얻은 이후, 저자들은 classification capability를 늘리기 위해, curriculum training regime를 사용해 보았다고 합니다.
- 그리하여, 해당 모델은 episode별로 fifteen class를 구별하는 태스크를 학습시키고, 10000개의 episode마다, episode당 제공되는 최대 클래스를 하나씩 증가시켜보았다고 합니다.
그 결과로, network는 training 동안 높은 정확도를 유지하였고, 100,000 episode가 지난 뒤에는(25 개의 class로 학습이 된 꼴) 50개의 class까지 잘 분류해 냈다고 하는 것 같습니다. 이렇게 학습을 계속하였더니, 100개의 class까지는 잘 증가하였다고 합니다.
Regression
저자들의 MANN 아키텍처는 meta-leraning을 위한 broad strategy를 만들어 냈기 때문에, 해당 모델이 never-before-seen function에 대한 regression task를 잘 수행하는지에 대해서 확인하고자 했다고 합니다.
- 이를 실험하기 위해, fixed set of hyper parameter들을 가지는 GP prior로부터 생성되는 함수들로 학습을 수행했다고 합니다.
입력으로는 x값과 time-offset function value f(x_(t-1))을 받았다고 하네요. 그 후, x_t를 예측하는 task인 것 같습니다.
제안하는 모델의 성능은, network에서 학습한 것과 동일한 순서로 제공된 sample의 실제 GP 예측과 비교되었다고 합니다.
- 중요한 점은, GP는 모든 data point에 대한 복잡한 query를 수행하는 것이 가능한 모델이라고 합니다.
- 이에 비해, MANN은 메모리에서 local update만을 수행하는 것이 가능하므로, GP의 기능을 대략적으로만 수행할 수 있다고 합니다.

Figure 5에서 볼 수 있듯, MANN 예측은 제공된 함수를 잘 따라가며, 이미 학습한 함숫값과 거리가 먼 값을 예측할 때에는 분산이 증가하는 것을 확인할 수 있었다고 합니다.

또한, 2 dim, 3-dim의 경우로 문제를 더욱 확장하였을 때에도 어느 정도 좋은 성능을 보여주었다고 합니다.
Discussion & Future work
많은 중요한 learning problem은 small amount of data로부터 빠르게, 그리고 새로운 정보에 대해서 조정이 가능할 수 있게 끔 지적으로?, 타당한 추론을 이끌어내는 능력을 요구한다고 합니다.
이러한 문제들은 일반적으로 느리고, 점진적으로 파라미터가 바뀌는 deep learning에 있어서는 특히 어려운 점이라고 합니다.
저자들은 meta-learning의 idea를 기반으로 하여 이 문제에 접근해 보았다고 합니다.
- 해당 논문에서, 점진적인 학습은 작업 전반에 걸쳐있는 background knowldedge를 encoding하는 반면, 보다 유연한 memory resource는 새로 마주치는 task들에 특정한 정보를 binding한다고 합니다.
저자들의 핵심 contribution은 meta learning을 위한 MANN의 유용성을 입증하는 것이라고 합니다.
- 이는 프로세스 제어를 구현하는 메커니즘으로부터 구조적으로 독립적인, 주소 지정이 가능한 전용 메모리 리소스를 포함하는 딥러닝 아키텍처라고 합니다.
- 해당 MANN은 희소 데이터 만을 사용하는 classification, regression 두 개의 meta-learning task들에서 LSTM보다 우수한 성능을 보여주는 것으로 확인되었다고 합니다.
“Inductive transfer”에 대해 언급.
Meta-leraning은 human intelligence의 core ingredient로써 인식되고 있다고 함. DNN에서의 huan skill들을 모델링하는 것에 있어서 최근의 성공들을 감안할 때, MANN이 human meta learning의 메커니즘에 대한 promising hypothesis를 내포하는 지를 묻는 것은 가치가 있다고 함 음..?
그러면서, 사람도 이긴 MANN의 성능을 강조. 하지만, memory가 task사이에서 비어있지 않을 때, MANN은 proactive interference로부터 고통을 받는다고 함. 이는 human memory and inference들에서 많이 연구되어 왔다고 함.
해당 연구를 제안하면서, 저자들은 next-stage development에 대한 몇몇 opening을 남겨두었다고 합니다.
- 저자들의 실험은 classification, regression 등의 task에 매우 적합한, 메모리에 writing하기 위한 새로운 절차를 구현해 낸 것이라고 함. meta- learning이 optimal memory addressing procedure를 스스로 발견할 수 있는지 여부에 대한 것을 고려하는 것이 흥미로울 것이라고 함
- 비록 저자들은 MANNs를 episode에 따라 task parameter가 변하는 셋팅에서 실험을 수행하였지만, 연구된 task들은 높은 수준의 high-level structure의 공유를 포함하고 있다고 함… 음 ⇒ 조금 더 넓은 범위의 task에 대한 학습은 catastrophic interference의 위험을 포함하는, continual learning과 관련된 standard challenge들을 다시 불러올 수 있을 수 있다고 합니다.
- 마지막으로, observation이 active하게 선택되어야 하는, active learning이 요구되는 meta-learning task들에서 MANN의 성능을 조사하는 것이 흥미로울 것 같다는 얘기를 남겼습니다.