가짜연구소 5기 멀티태스크메타러닝-초읽기 아카데믹 러너 활동을 통해 위의 논문을 읽게 되었습니다.
제가 주로 다루는 분야가 아니기에, 가볍게 정리하는 느낌으로 가져가 볼까 합니다.
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
Abstract
- 저자들은 classification, regression, 그리고 강화학습을 포함하는, 다양한 서로 다른 학습 문제들에 적용 가능한, 그리고 gradient-descent로 훈련되는 모델에 호환 가능한, model-agnostic meta-learning알고리즘을 제안했다고 함.
- meta-learning의 목적은 small number of training sample만으로, 새로운 learning task를 해결할 수 있게 되어, 모델이 다양한 learning task를 학습할 수 있게 하는 것이라고 함.
- 저자들의 접근 방법은, model의 parameter들이 explicit하게 훈련되고, 그래서 새로운 task로부터 적은 훈련 데이터를 가지고 약간의 gradient step을 수행하더라도, 해당 task에 대해 good generalization 성능을 낸다고 함.
- 실제로, 저자들의 기법은 model을 조금 더 쉽게 fine-tuning할 수 있도록 훈련시킨다고 합니다.
- 저자들은 제안하는 기법이 두 개의 few shot image classification benchmark에서 SOTA성능을 이끌어 낼 수 있었고, few-shot regression에서도 좋은 성능을 냈으며, 그리고 NN policy를 가지는 PG 기반 RL의 fine-tuning을 조금 더 가속화시켰다고 합니다.
Introduction
Few example들로부터 object를 인식하는 것이나, 단지 몇 분만의 경험 이후에 새로운 skill들을 빠르게 학습하는 것 등을 포함하는, 빠른 학습은 인간 지능의 전형적인 특징이라고함.
우리의 artificial agent들은 이를 동일하게 할 수 있어야 하며, 더욱 많은 데이터들에 대해서 계속해서 적응이 가능해야 한다고 첼시 핀 교수는 얘기합니다.
이러한 fast and flexible learning들은 어려운데, 새로운 데이터에 대해서 overfitting되지 않으면서도, agent가 자신의 사전 지식을 적은 양의 새로운 정보에 통합해야 하기 때문이라고 합니다.
- 게다가, 사전 지식의 형태와 새로운 데이터는 task에 의존한다고 합니다.
이 연구에서, 저자들은 어떤 learning problem이나 gradient 기반으로 학습되는 모델에 직접적으로 적용할 수 있는, 일반적이고, model을 알 필요가 없는(이 해석이 맞을지 모르겠네요) meta-learning algorithm을 제안한다고 합니다.
- 저자들의 초점은 DNN model이며, 뿐만 아니라 저자들은 어떻게 제안한 기법이 분류, 회귀 그리고 PG류 RL 등을 포함하는 different architectures and problem setting에 쉽게 적용이 가능한 지를 보여준다고 합니다.
Meta-leaerning에서, 학습된 모델의 목표는 적은 양의 새로운 데이터로부터 new task를 빠르게 배우는 것이라고 하며, model은 meta-learner에 의해서 많은 수의 다른 task들을 배울 수 있게 된다고 합니다.
저자들이 제안한 기법의 key idea는!! 새로운 태스크로부터 small amount of data를 통해 한 번 혹은 여러 번의 gradient step을 통해서 업데이트가 되면, 해당 태스크에서 maximal performance를 model이 가질 수 있도록, model의 initial parameter들을 훈련시키는 것이라고 합니다.
- 말이 조금 어렵지만, one-shot 혹은 few-shot등에 대비하기 위해, 다양한 task에 대해서 general 한 weight update를 large dataset으로 끝내 놓고(이를 initial parameter setting으로 표현), 그다음에 one-shot 혹은 few-shot을 대비하는 느낌으로 저는 이해했습니다.
기존의 update function 혹은 update rule을 학습하는 meta-learning method들과 달리, 저자들의 알고리즘은 num of learned parameter들을 확장시키거나, model architecture에 제한을 두는 등의 방식을 사용하지 않았고, MLP, CNN, RNN 계열들에도 쉽게 combine 할 수 있다고 합니다.
- 또한, 이는 지도 학습 계열의 loss, 그리고 RL objective 등의 다양한 loss function들에서도 사용할 수 있다고 합니다.
Few or even a single gradient step과 같이 model의 parameter들을 훈련시켜서 새로운 task에서 좋은 결과를 생성할 수 있도록 하는 프로세스는, 다양한 task들에 대해 광범위하게 적합한 internal representation을 구축하는 feature learning 관점으로써 볼 수 있다고 합니다.
- 만약 internal representation이 많은 task들에 적합하다면, 간단히 fine-tuning을 함으로써, 좋은 결과를 낼 수 있을 거라고 핀 교수는 말합니다.
사실, 저자들의 model을 최적화하는 절차는 빠르고 쉽게 fine-tune할 수 있다고 하며, 빠른 학습을 통해 올바른 sapce에 적응하는 것을 가능하게 해 준다고 합니다.
- dynamical system관점에서, 저자들의 learning process는 parameter들에 대해 새로운 task의 loss function들에 대한 민감도를 최적화하는 관점으로써 볼 수 있다고도 합니다. (hessian이 나오는…ㅎ)
- ⇒ sensitivity가 높다면, small local changes to the parameters가 task loss의 large improvement를 이끌어 낼 수 있다고 합니다.
이 연구의 primary contribution은 적은 수의 gradient update가 new task에 대한 빠른 학습으로 이어질 수 있도록, 모델의 parameter들을 학습하는 meta-learning을 위한, simple model 및 task-agnostic algorithm이라고 합니다.
- 저자들은, 해당 알고리즘이 여러 다른 model type들에서 동작하는 것을 보여준다고 합니다.
- 저자들의 실험 평가는 제안한 meta-laerning 알고리즘이 classification을 위해 설계된 SOTA one-shot method들에 근접할 뿐만 아니라, 더 적은 parameter를 갖는다는 것과, regression, rl 등의 다른 domain에서도 쉽게 적용될 수 있음을 보여주었다고 합니다.
Methodology(Model-Agnostic Meta-Learning)
저자들은 rapid adaptation을 달성할 수 있도록 모델을 학습시키는 것을 aiming 했다고 합니다. 문제 정의는 few shot learning으로 형식화했다고 하네용
해당 section에서, 저자들은 problem setup과 저자들의 알고리즘의 general form을 제공한다고 하네요.
Meta-learning problem set-up
Few-shot meta-learning의 목적은 단지 few data points와 training iteration만으로, new task에 빠르게 적응할 수 있는 모델을 학습하는 것이라고 합니다.
- 이를 달성하기 위해, model or learner는 set of task들에 대해 meta-learning phase동안 훈련되고, trained model은 small number of examples만을 통해 net task에 빠르게 적응할 수 있어야 한다고 합니다.
해당 섹션에서, 저자들은 meta-learning problem setting을 differnt learning domain들의 간단한 예제를 포함하는, general manner로 형식화한다고 하네용
저자들은 model을 observation x를 output a로 mapping하는 f로써 명명했다고 합니다. meta-learning동안, model은 large or inifite num of task에 적응할 수 있게끔 훈련이 된다고 합니다.
- 저자들은 자신들의 framework가 다양한 learning problem에 적용될 수 있도록, generic notation of a learning task를 다음과 같이 소개한다고 합니다.

저자들은 각 task를 T로 명명하고, RL혹은 sequential task까지를 포함할 수 있도록 하기 위해, episode length H라고 하는 변수를 포함하도록 정의한 것 같습니다. ⇒ 역시나, 다양한 분야에 정통한 천재 박사는 남들과 다른 생각을 할 수 있는 것 같습니다. 그들의 노력에 박수를 보냅니다..
저자들의 meta-learning 시나리오에서, 저자들은 자신들의 model이 적응하는 것을 기대하는 task들의 분포 p(T)를 고려했다고 합니다.
- K-shot learning setting에서, 모델은 q_i로부터 draw된 K sample들로부터, p(T)에서 draw된 net task T_i와, T_i로부터 생성된 feedback L_(T_i)를 통해서 학습이 된다고 합니다.
meta-training 동안에는 task T_i는 p(T)에서 샘플링되고, model은 해당 task에서부터 L_(T_i)와 K sample을 가지고 훈련이 되고, new samples from T_i에서 평가가 된다고 합니다. (same task, new sample)
- meta learning이 끝나는 시점엔, new task 가 p(T)로부터 sampling되고, eta-performance가 new task에 대한 K sample을 통해 학습된 이후 측정된다고 합니다.
- 일반적으로, meta-testing때 사용되는 task들은 meta-training중에는 보류(hold-out)가 되었던 친구들이라고 합니다.
Model-Agnostic Meta-Learning Algorithm
Entire dataset을 입력받는 RNN 계열을 훈련시키거나, test time에 non-parametric method들과 결합되기 위해 feature embedding을 입력 받는 식의 이전 연구들과는 대조적으로, 저자들은 어떤 표준 모델의 parameter들이라도 fast adaptation을 준비할 수 있게, meta-learning을 통해 학습할 수 있는 기법을 제안했다고 합니다.
- 이러한 접근의 intuition은, “어떤 internal representation이 다른 것들에 비해 transferrable할까?” 였다고 합니다.
- 예를 들어, neural network는 single individual task보다는 모든 task에 넓게 적용 가능한 internal feature를 배울 수 있다.
우리는 어떻게 이러한 일반적인 목적의 representation의 출현을 촉진할 수 있을까?
- 저자들은 이러한 문제의 explicit approach를 다음과 같이 삼는다고 함: model이 새로운 task에 대해 gradient-based learning rule을 이용해서 fine-tuning될 것이기 때문에, 저자들은 overfitting 없이, p(T)로부터 draw된 새로운 task들에 대해 빠르게 학습할 수 있는 model을 학습하는 것을 aiming한다고 함.
실제로, 저자들은 figure 1과 같이, loss의 gradient의 방향이 바뀌었을 때, parameter의 small change가 p(T)에서 darw된 어떤 task의 loss function이라도 많은 개선을 만들어 낼 수 있도록, task의 change에 sensitive한 model parameter를 찾는 것을 aiming한다고 함.
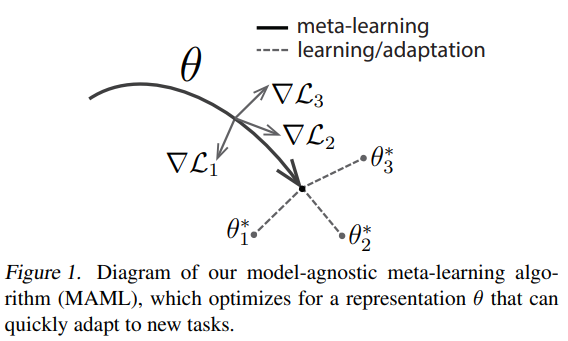
저자들은 model의 parameter가 theta라는 것과, loss function이 gradient-descent 기법을 적용할 정도로 충분히 smooth하다는 것 정도 이외에, model의 형태에 아무런 가정을 하지 않았다고 함.
Formally, 저자들은 parameterized function f_theta에 의해서 표현된 모델을 고려한다고 함. new task T_i에 model parameter를 적응하면 theta ⇒ theta’_i로 변한다고 함.
저자들의 기법에서, updated parameter vector theta’_i는 하나 혹은 그 이상의 gradient descent update를 task T_i에서 계산한다고 함. 예를 들면, one gradient update의 경우, alpha라는 learning rate(hyper param)를 가정하여 다음과 같이 정의!
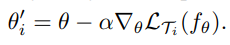
그러면 모델의 파라미터들은 f_(theta’_i)를 theta와 다양한 task들에 대해서 최적화하기 위해 훈련된다고 함! 더욱 구체적으로, meta-objective는 다음과 같이 정의한다고 합니다.
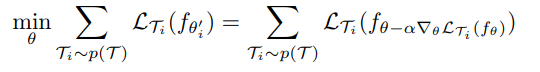
Meta-optimization은 parameter theta에 대해서 수행되고, 반면에 objective는 updated model parameter theta’에 의해서 계산된다고 함. 사실, 저자들의 method는 이러한 newt task에 대한 one or small # of gradient stop이 해당 태스크에 대한 효율을 최대로 하는 것을 목적으로 한다고 합니다.
여러 task들에 대한 meta-optimization은 SGD를 통해 수행된다고 하며, 그래서, model parameter theta는 다음과 같이 업데이트가 된다고 하네요. (beta는 meta step size라고 합니당.)
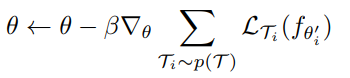
MAML meta-gradient update는 gradient through gardient를 포함하고 있다고 합니다. 계산적으로, 이는 hessian vector를 계산하기 위해, 추가적인 backward process를 필요로 한다고 하는데요, 이는 표준적인 DL library라면 지원을 해준다고 합니당.
- 저자들의 실험에서, 저자들은 또한 first-order approximation을 이용해서 해당 backward pass를 수행하지 않는 trick을 제안하고 이를 비교해 보았다고 합니다ㅎ
Species of MAML
해당 섹션에서, 저자들은 지도 학습과 강화학습에 대한 저자들의 meta-learning algorithm에 대한 구체적인 사례를 보여준다고 합니다.
- 해당 도메인들은 loss function면에서 차이가 존재하고, task가 generate되고 model을 표현하는 방법 면에서 조금 다르다고 합니다. 하지만, both cases에 대해, 제안한 adaptation mechanism은 동일하게 적용될 수 있음을 보여준다고 합니다.
Supervised regression and classification
(중략)
Supervised regression과 classification problem을 meta-learing의 문맥에서 형식화하기 위해, 저자들은 horizon H를 1로 두고, time step subscript t를 x_t에서 뺐다고 합니다.
- 그리하여, regression과 classification의 loss는 다음과 같이 표현했습니다. regression: L2 loss, classification: cross-entropy

Conventional terminology에 따라, K-shot 분류 task는 N-way 분류를 위한 총 NK data points에 대해 각 class에 대해 K개의 intput/output pair를 사용했다고 합니다.

Task distribution p(T_i)가 주어지면, 위의 loss function들은 algorithm 2에 도시된 것처럼, meta-learning을 수행하기 위해 theta를 업데이트하는 위의 방정식들(MAML 본체 방정식!!)에 직접적으로 사용될 수 있다고 합니다.
Reinforcement learning
강화학습에서, goal of few-shot meta-learning은 test setting에서 small amount of experience만을 사용해서 net task에 대한 policy를 빠르게 얻는 것이 가능하게 하는 것이라고 합니다.
- 새로운 task는 new goal을 달성하는 것을 포함할 수도 있고, new environment에서 이전에 학습된 목표를 이어받는 것일 수도 있다고 합니다.
- 예를 들어, agent는 new maze를 마주쳤을 때, 어떻게 탈출해야 하는지 빠르게 학습하는 것 등이 있다고 합니다.
- 이 섹션에서, 저자들은 MAML이 어떻게 RL을 위한 meta-learning에 적용될 수 있는지 다룬다고 하네용
각 RL task T_i는 initial state distribution q_i(x_1)과 transition distribution q_i(x_(t+1) | x_t, a_t) 그리고 reward function R에 따른 loss L_(T_i)를 포함한다고 합니다.
- 전체 task는 MDP with horizon H이며, 여기서 learner는 few-shot learning을 위해, 제한된 수의 sample trajectory들을 query 할 수 있다고 합니다. 또한, MDP의 측면은 task p(T)에 따라 달라질 수 있다고 합니다.
model이 학습되면, f_theta는 각 time step t \in {1, …, H}에 state x_t로부터 action a_t를 mapping하는 정책이라고 합니다. 해당 task T_i를 위한 loss와 model f_phi는 다음과 같이 형성된다고 합니다.

K-shot RL에서, task T_i와 f_theta로부터 얻은 K개의 rollout들 그리고, 그에 따른 reward R(x_t, a_t)들은 new task T_i에 adaptation을 함에 있어서 사용이 된다고 합니다.
Expected reward가 일반적으로 unknown dynamics로 인해 미분이 불가능하기 때문에, 저자들은 model gradeint와 meta optimization을 위해 gradient를 추정하는 데 있어서 PG method를 사용했다고 합니다!
- Policy gradients는 on-policy algorithm이기 때문에, f_theta를 적용하는 동안 각 additional gradient step에서는 현재 정책 f_theta_i의 new sample들이 요구된다고 합니다.

저자들은 이를 algorithm 3에 자세히 서술해 두었다고 합니다. 이 알고리즘은 Algorithm 2와 동일한 구조를 가지고 있다고 하며, 주된 차이는 step 5, step8에서 sampling trajectory를 필요로 한다는 점이라고 합니다. (datapoints ⇒ trajectories)
- 이 기법을 구현함에 있어서, 최근에 제안된 pg algorithm(TRPO 등)들을 포함하여, 다양한 rl 알고리즘을 사용할 수 있을 것이라고 핀 교수는 얘기합니다.
Related work
저자들이 해당 논문에서 제안한 기법은 few-shot learning을 포함하는 meta-learning의 일반적인 문제를 해결한다고 함.
Meta-learning을 위한 popular approach는 leaner’s model의 parameter update를 어떻게 할지에 대해 학습하는 meta-learner를 훈련시키는 것이라고 합니다. 어우 복잡해… 비문 같네요.
- 최근의 접근 중 하나는 few-shot image recognition을 위해서, weight 초기화와 optimizer 둘 다를 학습한다고 합니다. 으흠..?
저자들은 이러한 기법들과는 달리, MAML learner의 weight은 learned update 대신 gradient를 이용해서 업데이트가 된다고 하며, 또한, 저자들의 기법은 meta-learning을 위한 추가적인 파라미터를 도입하지 않았다는 점과, 특별한 learner architecture를 요구하지 않는 점을 강조하고 있습니다.
Few-shot learning 기법들은 또한, generative modeling이나 image recognition과 같은 특별한 task들을 위해 개발되어 왔다고 합니다.
- Few-shot classification을 위한 하나의 성공적인 접근은 learned metric space에서 new example들을 비교하는 방법을 학습하는 것이라고 합니다. 예를 들면 Siamese network, recurrent with attention(Vinyals et al 2016 등) 등이 있다고 합니다.
- 이러한 접근 법들은 몇몇 성공적인 결과들을 생성해 왔지만, RL과 같은 다른 문제들로 직접적인 확장을 하기에는 어려움이 있었다고 합니다.
- 이와 대조적으로, 저자들의 기법은 model의 형태나 learning task를 가리지 않는다고 합니다. agnostic!
Meta-learning의 다른 접근은 다양한 태스크에 대해 memory augmented model을 학습시키는 것입니다. 일반적인 memory augmented model에서는, recurrent learner이 새로운 작업이 roll out되면, 이에 적응하도록 훈련이 됩니다.
- 이러한 network들은 few-shot image recognition에 적용되기도 했고, rl agent들을 빠르게 학습하기 위해 적용되기도 했다고 합니다.
- 저자들의 실험은 few-shot classification에서 이러한 recurrent approach들을 뛰어넘는 성능을 보여주었다고 합니다.
게다가, 이러한 모델들과는 달리, 저자들의 접근은 단순히 learner와 meta update모두에게 same gradient descent를 사용하고, 좋은 초기 가중치를 제공한다고 합니다.
- 결과적으로, 이는 additional gradient step에 대해 learner를 fintune하는 것을 간단하게 해 줍니다.
저자들의 접근법은 또한 심층 네트워크들을 초기화하는 방법과 관련이 있다고 합니다. 컴퓨터 비전에서, large-scale image classification에서 pretrain된 모델들은 다양한 범위의 문제들에서 feature를 효율적으로 학습한다는 것을 보여주어 왔다고 합니다.
- 대조적으로, 저자들의 기법은 모델이 only a few example들 만으로 새로운 태스크들에 적응할 수 있게 하는, fast adaptability를 위해 모델을 명시적으로 최적화한다고 합니다.
저자들의 기법은 또한, 모델 파라미터들에 대한 new task losses의 민감도를 명시적으로 최대화하는 것으로 간주할 수도 있다고 합니다. 진짜 똑똑쓰
- 몇몇 이전의 연구들은 deep network들의 sensitivity를 탐험했다고 하며, 이는 종종 초기화와 관련된 context에서 이루어졌다고 합니다.
- 대부분의 이러한 연구들은 good random initialization을 고려한다고 합니다. 비록 많은 수의 논문들이 data dependent한 initializer를 해결했지만 말이죠.
- 대조적으로, 저자들의 기법은 주어진 task distribution에서의 parameter들의 sensitivity를 명시적으로 훈련할 수 있으며, 그리하여 K-shot learning이나 rapid reinforcement learning 등을 only one or a few gradient setep만으로 극한의 효율적인 adaptation을 할 수 있게 해 준다고 합니다.
Experimental Evaluation
저자들의 실험 평가의 목표는 다음의 질문에 답하기 위한 것이라고 합니다.
(1) Can MAML enable fast learning of new tasks?
(2) Can MAML be used for meta-learning in multipld different domains, including supervised regression, classifcation, and reinforcement learning?
(3) Can a model learned with MAML continue to improve with additional gradient updates and/or examples?
모든 저자들이 고려하는 meta-learning problem들은 test-time에서 new task에 어느 정도 적응을 해야 한다고 합니다. 가능한 경우, 저자들은 자신들의 결과를 모델의 성능에 대한 상한으로 task에 대해 이미 알고 있는 오라클로 설정하여 비교를 수행했다고 합니다.
- 저자들은 tf를 썼다고 합니다 크크 코드 공개도 했다네용
Regression
저자들은 MAML의 기본 원리를 설명하기 위해, 단순한 regression 문제로 시작했다고 합니당. 각 태스크는 sine wave로, 크기나 위상 등을 바꾸면서 테스트했다고 하네용
- Amplitude는 0.1~5.0, phase는 0~pi로, input/output dimension은 1로 했다고 합니다.
- Input x는 [-5~5] 사이를 균일하게 sampling하였고, loss는 MSE로 했답니다. neural network는 40 node의 hidden layer 2층, ReLU 등등을 사용!
- Few shot K의 size는 10, step size는 0.01, Adam optimizer를 사용했다고 합니다.
성능을 평가하기 위해, 저자들은 single meta-learned model을 K개의 varying number of K examples에 대해서 fine tuning했다고 하고, 두 개의 baseline들과 비교를 수행했다고 합니다.
(a): pretraining on all of tasks ⇒ fine tuning with gradient descent on K provided points, using an automatically tune step size
(b): oracle receives the true amplitude and phase as input

저자들은 MAML로 학습되고 파인튜닝된 모델의 성능을 평가했는데, 이때 K={5, 10, 20}일 때 평가했다고 합니다.
- Fine-tuning동안, 각 gradient step은 same K datapointes를 사용해서 계산이 되었다고 합니다.
- 정성적인 평가는 Figure 2, Appendix B에 있다고 합니당 ⇒ MAML로 프리트레인되고, 학습된 모델은 5개의 data만으로도 빠르게 적응하는 것을 보여주었는데, 그냥 지도학습으로 프리트레인된 친구는 catastrophic overfitting없이 적응하는 것이 불가능했다고 합니다 크…
- 중요한 점은, K datapoints들이 모두 one half of the input range에만 있었으며, MAML로 trained된 모델은 other half of the range에 있는 amplitude와 phase마저 추론해낼 수 있었다는 것이라고 합니다. 대박쓰..
- 게다가, 저자들은 정량적인 평가마저도 MAML로 학습된 모델이 조금 더 좋은 성능을 보인 것을 Figure 3을 통해서 보여주었다고 합니다.

이러한 개선점은 MAML이 parameter를 최적화하여, 그 값들이 p(T)내의 task들의 손실 함수에 대해 민감하고, 빠른 적응이 가능한 영역에 놓이도록 하는, 2.2에서 논했던 것을 보여주고 있다고 합니다.
Classification
이전의 meta-laerning and few-shot learning algorithm들과 비교하여 MAML을 평가하기 위해, 저자들은 MAML을 Omniglot and MiniImagenet dataset에서의 few-shot recognition에 적용해 보았다고 합니다.
- Omniglot dataset은 50개의 다른 알파벳들로부터 1623개의 캐릭터 별로, 20개의 instance만을 가진 dataset이라고 합니다. 이때, 각 instance들은 different person으로부터 얻어졌다고 하네요.
- MiniImagenet dataset은 Ravi, Larochelle(2017)에 의해 제안되었으며, 64개의 training classes, 12개의 validation classes 그리고 24개의 test classes를 포함하고 있다고 합니다.
Omniglot and MiniImagenet image recognition task들은 few-shot learning benchmark들에서 최근 가장 많이 사용되었었다고 하네용
- 저자들은 Vinyals가 제안한, N-way classification with 1 or 5 shots에서의 빠른 학습을 포함하는 실험 프로토콜을 따랐다고 합니다.
- N-way classification problem은 다음과 같이 셋업 된다고 합니다: N개의 unseen classes를 선택하고, 각 N class마다 K개의 다른 instance들을 모델에게 제공해준다. 그다음, N개의 class에서, new-instance를 분류할 수 있는지에 대한 능력을 평가한다.
Omniglot에서, 저자들은 1200개의 character를 임의로 선정해 학습에 사용하고, 나머지를 testing에 사용했다고 합니다. Omniglot dataset은 Santoro 등이 제안한 것처럼, 90도씩 회전한 데이터들로 증강해서 사용했다고 합니다.
저자들의 모델은 Vinyals가 사용한 것과 동일한 4 modules with a 3x3 convolutions and 64 filters를 embedding function으로 사용하였고, batch norm, ReLU, 2x2 max-pooling 등등을 사용했다고 합니다.
- 또한, Omniglot imaga는 28 x 28로 다운샘플링 해서 사용했다고 하며, 그리고 last hidden layer의 차원은 64로 했다고 합니다. (…. 중략)
- 그리고, Santoro 등이 제안한 memory-augmented neural network과 공정한 평가를 하기 위해, MLP에서도 학습을 수행했다고 합니다.
결과는 Table 1에 도시되어 있다고 합니다. convolutional model은 해당 task에서 SOTA 결과를 보여주었으며, 기존의 기법들을 좁은 보폭으로 제쳤다고 써두었습니다.
- 좁은 보폭으로 제끼긴 했지만, 이러한 기존의 기법들은 rl과 같은 도메인에는 적용하기가 쉽지 않다고 얘기를 하고 있습니다.
- 추가적으로, MAML로 학습된 모델은 더 적은 전체적인 파라미터를 사용한다고 하며, 이는 분류기 자신이 사용하는 weight이외에 additional parameter를 도입하지 않았기 때문이라고 합니다.
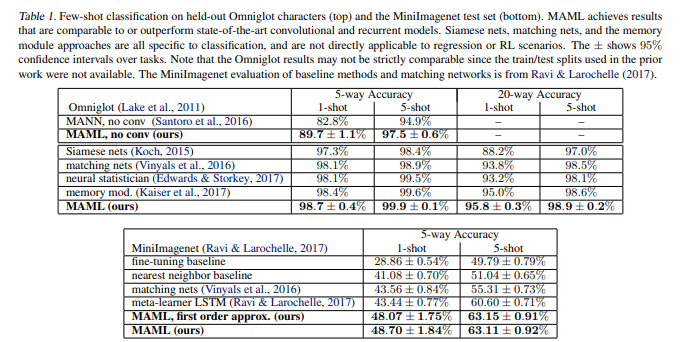
MAML의 상당한 계산 비용은 meta-objective에서의 gradient 연산을 통한 meta-gradient를 역전파 할 때, 2계도 미분이 사용되기 때문이라고 합니다. MiniImagenet에서, 저자들은 2계도 미분을 생략한 MAML의 first-order approximation과 MAML의 비교를 했다고 합니다.
- 이는 신기하게도, 거의 같은 결과를 가져왔다고 합니다 와우 TRPO, PPO가 떠오르네요. ⇒ 계산 속도는 대략 33% 정도 향상되었다고 합니다.
Reinforcement learning
RL problem에서의 MAML을 평가하기 위해, 저자들은 몇몇 task 집합을 구축했다. → continuous control environments in the rllab.
- 저자들은 개별 domain에 대해서 아래에서 논한다고 합니다. 모든 도메인에서, 모델들은 MAML로 훈련되고, 100개의 node를 가지는 two hidden layer의 policy + ReLU가 사용되었다고 합니다.
- gradient update방법으로는 vanilla PG가, meta-optimizer로는 TRPO가 사용되었다고 합니다.
- ⇒ 이렇게 되면, 3계도 미분에 대해서 계산해야 하기 때문에, TRPO의 hessian ector product를 계산하기 위해서 유한 차분을 사용했다고 하네용.
이러한 learning과 meta-learning에서, 저자들은 standard linear feature baseline을 사용했다고 합니다. 응? 이는 배치에서 샘플링된 각 task에 대해 각 iteartion마다 별도로 fit되는 거라고 하는데 무슨 소리징
저자들은 3개의 baseline model들을 비교했다고 합니다.
(a) pretraining one policy on all the tasks and then fine-tuning
(b) training a policy from randomly initialized weights
(c) an oracle policy which receives the parameteres of the task as input, which for the tasks below corresponds to a goal position, goal direction, or goal veloicty for the agent.
2D Navigation
첫 번째 meta-RL 실험에서, 저자들은 2D에서 agent에게 differnent goal position으로 움직이게끔 하는 task를 먼저 연구했다고 합니다.
- observation은 현재의 2D position과 action 그리고 속도로 했다고 하네용. reward 같은 경우는 negative squared distance to the goal로 했고, episode는 100 step에 다다르거나, goal에 0.01 이내로 가까워지면 끝난다고 합니당
MAML로 훈련된 policy는 20 trajectory를 가지고 한 번 PG를 경험시켜서 성능을 극대화시킨다고 했습니당. fine tune 과정 얘기한 것 같네용.
- 평가를 할 때는, 4 gradient step까지 net task를 적응시켜서 결과를 비교했다고 하며, 그 결과는 Figure 4에 도시했다고 합니다.
- 실험 결과, MAML의 adaptation performance가 다른 친구들보다 좋은 것을 잘 확인할 수 있었습니다.

Locomotion
MAML이 복잡한 deep RL에 어떻게 잘 확장할 수 있는지 연구하기 위해, 저자들은 또한 high-dimensional locomotion task에 adaptation하는 연구를 수행했다고 합니다.
- 해당 task는 (…중략)
- 또한, episode별 step수 즉, horizon H는 200으로, 20 rollouts per gradient step을 모든 문제에 대해서(ant의 경우만 40으로) 적용했다고 합니다.
- 결과는 figure 5에서 보여주고 있으며, MAML이 single update만으로도 속도와 방향을 잘 잡는 것을 보여주었다고 합니다.
- 결과는 또한, 이러한 challenging task들에서도 MAML initialization이 random initaialization과 pretraining에 비해 상당히 우월한 성능을 가진다는 것을 보여준다고 합니다.

Discussion & Future work
저자들은 gradient descent를 통해 model parameter를 easily adaptable하게 학습할 수 있는 meta-learning 기법을 소개했다고 함
저자들의 접근은 여러 이점을 가지고 있다고 함.
- 제안한 모델은 간단하고, 다른 meta-learning을 위한 learned parameter들을 도입하지 않는다고 함.
- 또한, gradient based training이 가능한 모든 model representation과, 분류, 회귀, 강화학습을 포함하는 어떤 differentable objective들과 결합이 가능하다고 합니다.
- 마지막으로, 저자들의 기법은 단순히 weight initialization을 생성하기 때문에, 실험에서 사용한 특정 문제(one or five examples per class에 대한 분류 문제)에 대해서 SOTA를 찍었음에도 불구하고, 더욱 많은 데이터와 더욱 다양한 gradient step에서도 사용이 가능하다는 것을 얘기했습니다. (그러니까 실험한 것 이외에 더 확장이 가능하다! 라는 걸 강조하는 것 같습니다.)
게다가, 저자들은 제안하는 기법이 매우 modest한 양의 경험들로, PG기반의 RL agent가 adapt를 할 수 있다는 것도 보여주었다고 합니다.
과거의 task로부터 얻은 지식을 재활용하는 것은 DNN과 같은 high-capacity scalable model 작은 data set으로 빠르게 훈련할 수 있도록 만드는 데에 있어 중요한 재료라고 합니다.
저자들은, 이 work이 어떤 문제 그리고 어떤 모델에도 적용할 수 있는 simple and general-purpose meta-learning technique면에서 한 스텝 나아갈 수 있게 해 준 work이 되리라 믿는다고 합니다.
Further research in this area can make multitask initialization a standard ingredient in deep learning and reinforcement learning.