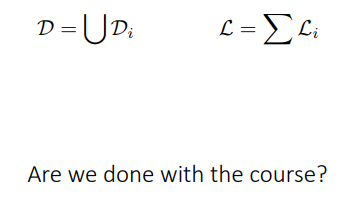가짜연구소 5기 멀티태스크메타러닝-초읽기 아카데믹 러너 활동을 통해 위의 강의를 듣게 되었습니다.
해당 스터디 활동의 조건은, 스터디에 참여하지 않은 사람들도 공부를 함께 할 수 있도록 하는 것이 원칙 중 하나기에, 스터디 과정 내 요약한 강의 요약본을 포스팅하게 되었습니다. 부족한 점이 있겠지만, 재미있게 봐주시면 감사하겠습니다!
Editor: 백승언
논문 링크: https://arxiv.org/pdf/1605.06065.pdf
목차
Remind CS-330 Lecture 3
Related code review - NTM, MANN
MANN 간단 정리
Abstract
Introduction
Methodology
Code review(구두 설명)
Remind CS-330 Lecture 3

meta-learning
long-term으로 특정 task를 위한 training data set에 대해 학습을 시킨 후, short-term으로, 학습에 사용되지 않은 data set에 대해 특정 task를 수행하거나, 혹은 학습에 사용되지 않은 task를 수행할 수 있게 학습하는 것?



학습에 사용되는 task i에 대한 training set을 D^tr_i, 학습에 사용되지 않아, 모델이 절대 볼 수 없는 task i에 대한 test set을 D^test_i라고 하는 것 같다.
- k-shot learning: class 별로 k개의 example만을 보여주고, 결과를 예측하는 task

대표적인 meta-learning을 위해 사용할 수 있는 데이터셋인 Omniglot dataset. class는 10개에, data가 엄청 많은 MNIST와 달리, class는 1600여 개에, 클래스별 데이터가 20개밖에 없어서 MNIST의 전치 버전이라고 불린다고 한다.
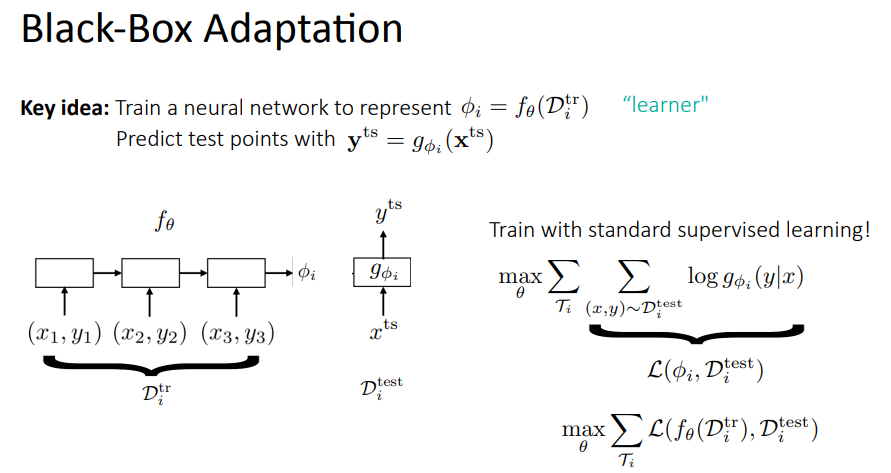
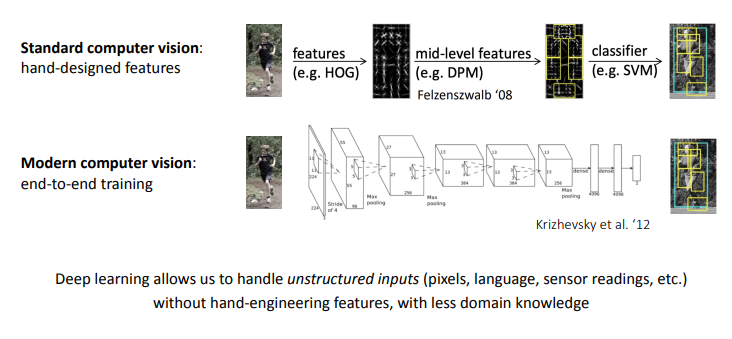
Black-box adaptation ⇒ neural network가 training data set을 통해 특정 변수 phi_i를 학습하게 하고, 이 phi를 이용하는 black box model g를 통해서, test data set의 본 적 없는 x^ts를 통해 y^ts를 예측하는 것
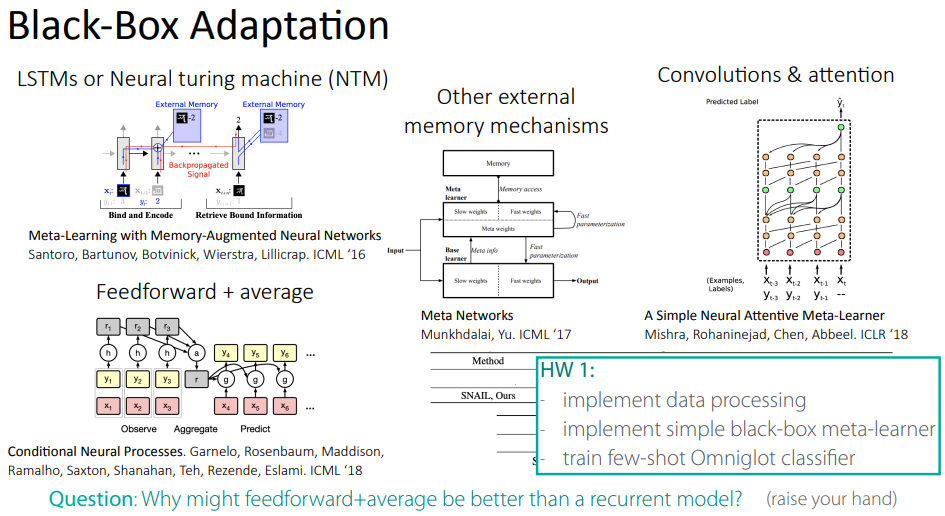
대표적인 black-box adaptation 모델로써 여러가지 모델들이 소개되었으며, DeepMind에서 연구한 NTM, MANN이 대표적인 모델인 것 같다.
Related code review - NTM, MANN

해당 강의의 경우, 해당 수업의 과제로써 data set processing과, 대표적인 black-box meta-learner 중 하나인 MANN을 구현해 오는 것을 과제로 주었다.
물론, 구현을 from scracth로 요구하지는 않고, 코드 조각 내에 핵심적인 코드만을 작성할 수 있게끔 배려를 해주었던 것 같다.
이 글에서도, MANN의 코드를 간단히 리뷰하고자 하며, 그 이전에, MANN에 대해서 간단하게만 정리를 한 후, 코드를 리뷰하고자 한다.
MANN 간단 정리
Abstract
최근 들어, 늘어나는 DNN의 성공에도 불구, one-shot learning은 어려운 점이 많다.
전통적인 gradient 기반의 네트워크들은 새로운 데이터를 마주치게 되었을 때, 해당 데이터로 parameter update를 하면 안 된다. 이때 catastrophic forgetting이 일어날 수 있기 때문. 그래서 처음부터 다시 학습해야 하는 어려움이 있다.
이전 연구인 NTM(Neural turing machine)과 같은 memory를 가지고 있는 구조는 새로운 정보를 빠르게 encode, retrive할 수 있는 능력을 제공하며, 기존의 고전적인 model들의 단점을 피할 수 있다.
저자들은 제안하는 MANN이 기존의 memory를 쓰는 기법들과 다르게, memory contents에 초점을 맞추어 external memory에 접근할 수 있는 기법이라고 하며, 좋은 성능을 보여주었다고 함
Introduction
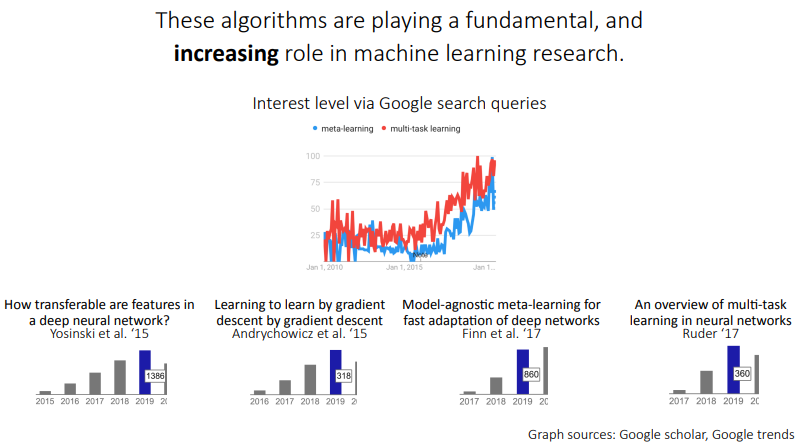
많은 흥미로운 문제들은 적은 양의 데이터로부터 빠른 inference를 요구한다고 함. 이러한 종류의 유연한 적응은 인간 지능의 유용한 측면이라고 함.
이를 위해 meta-leraning이라고 하는 기법들이 제안 되어왔으며, memory capacity를 가지는 신경망들이 제안되어 왔다고 함.
- 하지만, 이게 좋은 solution이 되려면, input data들이 안정적이고, element-wise로 접근이 가능하게끔 메모리에 저장이 되어야 한다고 함.
- 또한, parameter들의 숫자와 memory size는 연관이 있으면 안 된다고 함. (이미 internal memory를 가지고 있는, LSTM 계열 모델을 지적하려고 한 말인 것 같아요.)
위의 internal memory를 가지는 신경망의 단점을 극복할 수 있는 아키텍처가 2014년 Graves 등의 Neural Turing Machine, 2014년 Weston 등의 memory network 등으로 제안이 되어왔다고 합니다.
그러나, 저자들은 이러한 NTM과는 다르게, content로 접근이 가능한 memory access module을 설계하였으며, memory location을 이용하지 않았다고 합니다.
또한, 본 적 없는 Omniglot data set에 대해, 사람과 같거나 더 높은 정확도로 분류 task를 해결해낸 것을 보여준다고 합니다.
Methodology
Memory-Augmented Model
- NTM
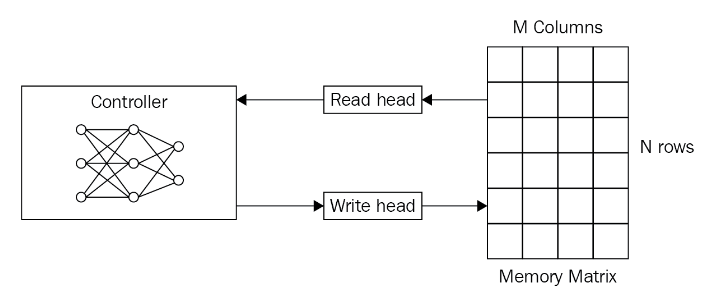
NTM은 read head, write haed들을 이용해 external memory module과 상호작용 하는 feed-forward or LSTM과 같은 controller로 구성이 되어 있다고 합니다.
- Controller: FF network or Recurrent model. It reads from and writes to the memory
- Memory: memory matrix or memory blank는 정보가 저장되는 공간. 메모리는 일반적으로 memory cell들로 구성된 two-dimensional matrix로 구성되어 있다고 합니다. 또한, memory matrix는 N rows, M column을 포함하고 있다고 합니다.
- Controller를 이용하면, 연구자들은 memory의 contents에 접근할 수 있다고 하며, controller는 external environment로부터 input을 받고, memory matrix와 상호 작용하여 응답(contents)을 출력해 낸다고 합니다.
- Read and write heads: read head와 write head는 해당 정보가 어디로부터 읽어와야 하고 어디에 쓰여야 하는지에 대한 주소를 포함하는 pointer들이라고 합니다.
또한, NTM은 external memory module에서 memory를 encode하고 retrive를 빠르게 한다고 합니다.
- LSTM, FF network를 사용하기에, gradient 기반의 최적화 방식을 이용하여 long-term storage가 가능하며, external memory module을 이용한 short-term storage가 모두 가능하기 때문에, low-shot prediction을 위한 meta-learning이 가능한 모델이라고 합니다.
- 초기의 NTM은 gradient를 통해 read/write head를 학습시키는 방법에 대해서 제안을 제대로 하지 못했던 것 같습니다. (뇌피셜)
그러나, NTM은 input의 type of representation 즉 contents를 아주 잘 활용하지는 못했던 것 같습니다. 저자들은 representation을 조금 더 활용하여 못 봤던 data에 대한 더욱 정확하고 빠른 예측을 위해 모델을 개선한 것 같습니다.
- 초기의 NTM은 gradient를 통해 read/write head를 학습 시키는 방법에 대해서 제안을 제대로 하지 못했던 것 같습니다. (뇌피셜^2)
- MANN
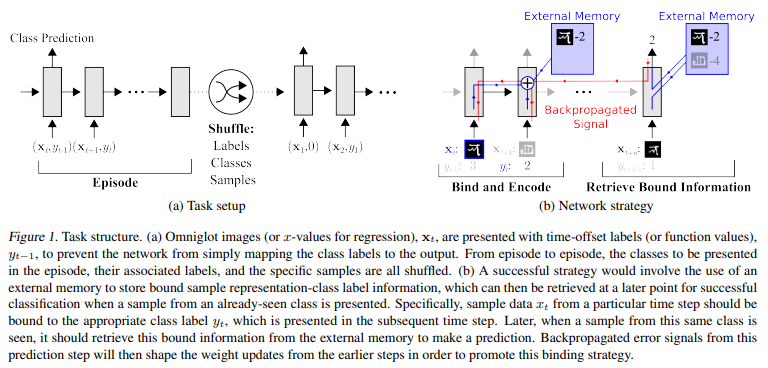
제안된 모델에서 사용하는 controller들은 기존의 NTM과 같이 FF network or LSTMs가 될 수 있다고 함. 제어기는 memory로부터 표현을 retreive하거나 place 하는 등에 있어서 input x_t를 십분 활용하고자 함.
- input x_t가 주어지면, controller는 memory matrix M_t의 행에 접근할 수 있는 key k_t를 만들어냄.
- 이때, M_t는 cosine similarity measure를 이용해 특정 지어진다고 함.
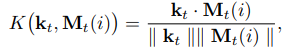
이를 이용해, read weight vector w^r_t를 만들어 낸다고 하며, memory r_t는 read weight vector를 통해서 retrive 된다고 합니다.
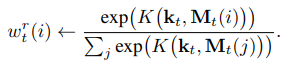
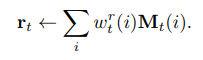
해당 메모리는 controller에서 classifier의 입력으로써도 사용하고, next controller state의 입력으로써도 사용할 수 있다고 하는 것 같습니다.
- Least Recently Used Access(LRUA)
기존의 NTM에서, memory들은 content와 location에 대해서 address되었다고 합니다. location-based addressing은 sequence-based prediction task에는 장점을 가지고 있지만, sequence에 대해 독립적인 정보를 가지고 있는 Omniglot 분류 등의 task에는 좋은 방법이 아니었다고 합니다.
- 이러한 이유로, 저자들은 memory에 정보를 써넣는 새로운 방법인 LRUA module을 제안했다고 합니다.
LRUA 모듈은 least used memory location / most recently used memory location에 memory를 write 하는 순수 content-based memory writer라고 합니다.
- 새로운 정보는 최근에 encoding된 정보를 보존하면서, 거의 사용하지 않는 위치에 기록되거나, 마지막으로 사용된 위치에 기록되며, 이는 보다 최신의 관련성 있는 정보로 메모리를 업데이트하는 기능을 할 수 있다고 합니다.
이는 이전의 read weight들 사이의 내삽, 그리고 weight w^u_t의 크기에 따라 일련의 식을 통해 만들어진다고 하며, 이러한 usage weight들은 각 time-step에 다음과 같은 식을 통해서 업데이트된다고 합니다.
- 이때, w^r_t는 위에서 계산된 식이며, least-used weights w^lu_t(i)는 w^u(t)를 이용해서 밑 밑 식을 통해 계산이 된다고 합니다. (m(v, n): n_th smallest element of the vector v, n: number of reads)
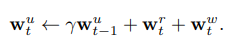
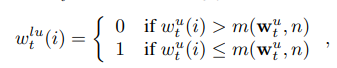
또한, write weights w^w_t의 경우, learnable sigmoid gate parameter로써 얻어졌으며, 직전의 read weight와 직전의 least-used weight을 convex 하게 combination 했다고 합니다.
- sigma: sigmoid function, alpha: scalar gate parameter.
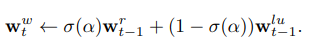
이렇게 write weight vector가 계산되면, memory에 정보를 써넣는 것은 다음과 같은 계산으로 이뤄진다고 합니다.
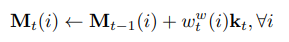
Code review(구두 설명)
class MANNCell():
def __init__(self, rnn_size, memory_size, memory_vector_dim, head_num, gamma=0.95,
reuse=False):
#initialize all the variables
self.rnn_size = rnn_size
self.memory_size = memory_size
self.memory_vector_dim = memory_vector_dim
self.head_num = head_num
self.reuse = reuse
self.step = 0
self.gamma = gamma
#initialize controller as the basic rnn cell
self.controller = tf.nn.rnn_cell.BasicRNNCell(self.rnn_size)
def __call__(self, x, prev_state):
prev_read_vector_list = prev_state['read_vector_list']
controller_input = tf.concat([x] + prev_read_vector_list, axis=1)
#next we pass the controller, which is the RNN cell, the controller_input and prev_controller_state
with tf.variable_scope('controller', reuse=self.reuse):
controller_output, controller_state = self.controller(controller_input, prev_controller_state)
num_parameters_per_head = self.memory_vector_dim + 1
total_parameter_num = num_parameters_per_head * self.head_num
#Initiliaze weight matrix and bias and compute the parameters
with tf.variable_scope("o2p", reuse=(self.step > 0) or self.reuse):
o2p_w = tf.get_variable('o2p_w', [controller_output.get_shape()[1], total_parameter_num],
initializer=tf.random_uniform_initializer(minval=-0.1, maxval=0.1))
o2p_b = tf.get_variable('o2p_b', [total_parameter_num],
initializer=tf.random_uniform_initializer(minval=-0.1, maxval=0.1))
parameters = tf.nn.xw_plus_b(controller_output, o2p_w, o2p_b)
head_parameter_list = tf.split(parameters, self.head_num, axis=1)
#previous read weight vector
prev_w_r_list = prev_state['w_r_list']
#previous memory
prev_M = prev_state['M']
#previous usage weight vector
prev_w_u = prev_state['w_u']
#previous index and least used weight vector
prev_indices, prev_w_lu = self.least_used(prev_w_u)
#read weight vector
w_r_list = []
#write weight vector
w_w_list = []
#key vector
k_list = []
#now, we will initialize some of the important parameters that we use for addressing.
for i, head_parameter in enumerate(head_parameter_list):
with tf.variable_scope('addressing_head_%d' % i):
#key vector
k = tf.tanh(head_parameter[:, 0:self.memory_vector_dim], name='k')
#sig_alpha
sig_alpha = tf.sigmoid(head_parameter[:, -1:], name='sig_alpha')
#read weights
w_r = self.read_head_addressing(k, prev_M)
#write weights
w_w = self.write_head_addressing(sig_alpha, prev_w_r_list[i], prev_w_lu)
w_r_list.append(w_r)
w_w_list.append(w_w)
k_list.append(k)
#usage weight vector
w_u = self.gamma * prev_w_u + tf.add_n(w_r_list) + tf.add_n(w_w_list)
#update the memory
M_ = prev_M * tf.expand_dims(1. - tf.one_hot(prev_indices[:, -1], self.memory_size), dim=2)
#write operation
M = M_
with tf.variable_scope('writing'):
for i in range(self.head_num):
w = tf.expand_dims(w_w_list[i], axis=2)
k = tf.expand_dims(k_list[i], axis=1)
M = M + tf.matmul(w, k)
#read opearion
read_vector_list = []
with tf.variable_scope('reading'):
for i in range(self.head_num):
read_vector = tf.reduce_sum(tf.expand_dims(w_r_list[i], dim=2) * M, axis=1)
read_vector_list.append(read_vector)
#controller output
NTM_output = tf.concat([controller_output] + read_vector_list, axis=1)
state = {
'controller_state': controller_state,
'read_vector_list': read_vector_list,
'w_r_list': w_r_list,
'w_w_list': w_w_list,
'w_u': w_u,
'M': M,
}
self.step += 1
return NTM_output, state
#weight vector for read operation
def read_head_addressing(self, k, prev_M):
"content based cosine similarity"
k = tf.expand_dims(k, axis=2)
inner_product = tf.matmul(prev_M, k)
k_norm = tf.sqrt(tf.reduce_sum(tf.square(k), axis=1, keep_dims=True))
M_norm = tf.sqrt(tf.reduce_sum(tf.square(prev_M), axis=2, keep_dims=True))
norm_product = M_norm * k_norm
K = tf.squeeze(inner_product / (norm_product + 1e-8))
K_exp = tf.exp(K)
w = K_exp / tf.reduce_sum(K_exp, axis=1, keep_dims=True)
return w
#weight vector for write operation
def write_head_addressing(sig_alpha, prev_w_r_list, prev_w_lu):
return sig_alpha * prev_w_r + (1. - sig_alpha) * prev_w_lu
#least used weight vector
def least_used(w_u):
_, indices = tf.nn.top_k(w_u, k=self.memory_size)
w_lu = tf.reduce_sum(tf.one_hot(indices[:, -self.head_num:], depth=self.memory_size), axis=1)
return indices, w_lu
#next we define the function called zero state for initializing all the states -
#controller state, read vector, weights and memory
def zero_state(self, batch_size, dtype):
one_hot_weight_vector = np.zeros([batch_size, self.memory_size])
one_hot_weight_vector[..., 0] = 1
one_hot_weight_vector = tf.constant(one_hot_weight_vector, dtype=tf.float32)
with tf.variable_scope('init', reuse=self.reuse):
state = {
'controller_state': self.controller.zero_state(batch_size, dtype),
'read_vector_list': [tf.zeros([batch_size, self.memory_vector_dim])
for _ in range(self.head_num)],
'w_r_list': [one_hot_weight_vector for _ in range(self.head_num)],
'w_u': one_hot_weight_vector,
'M': tf.constant(np.ones([batch_size, self.memory_size, self.memory_vector_dim]) * 1e-6, dtype=tf.float32)
}
return state
혹시나 끝까지 봐주신 분이 계시다면, 봐주셔서 감사하다는 말씀을 드리며 마무리 짓겠습니다!